Conceptos Básicos de Redux, Parte 7: Fundamentos de RTK Query
Esta página fue traducida por PageTurner AI (beta). No está respaldada oficialmente por el proyecto. ¿Encontraste un error? Reportar problema →
- Cómo RTK Query simplifica la obtención de datos en apps de Redux
- Cómo configurar RTK Query
- Cómo usar RTK Query para solicitudes básicas de obtención y actualización de datos
- Haber completado las secciones anteriores de este tutorial para entender los patrones de uso de Redux Toolkit
Si prefieres un curso en video, puedes ver este curso gratuito sobre RTK Query por Lenz Weber-Tronic, creador de RTK Query, en Egghead o ver la primera lección aquí mismo:
Introducción
En la Parte 5: Lógica Asíncrona y Obtención de Datos y la Parte 6: Rendimiento y Normalización, vimos los patrones estándar usados para obtener datos y almacenarlos en caché con Redux. Esos patrones incluyen usar thunks asíncronos para obtener datos, despachar acciones con los resultados, gestionar el estado de carga de solicitudes en el store y normalizar los datos en caché para facilitar búsquedas y actualizaciones de elementos individuales por ID.
En esta sección, veremos cómo usar RTK Query, una solución de obtención de datos y almacenamiento en caché diseñada para aplicaciones Redux, y cómo simplifica el proceso de obtener datos y usarlos en nuestros componentes.
Visión General de RTK Query
RTK Query es una potente herramienta para obtener datos y almacenarlos en caché. Está diseñada para simplificar casos comunes de carga de datos en aplicaciones web, eliminando la necesidad de escribir manualmente la lógica de obtención de datos y almacenamiento en caché.
RTK Query está incluido en el paquete de Redux Toolkit, y su funcionalidad se construye sobre otras APIs de Redux Toolkit. Recomendamos RTK Query como el enfoque predeterminado para obtener datos en aplicaciones Redux.
Motivación
Las aplicaciones web normalmente necesitan obtener datos de un servidor para mostrarlos. También suelen necesitar actualizar esos datos, enviar esas actualizaciones al servidor y mantener los datos en caché del cliente sincronizados con los datos del servidor. Esto se complica aún más por la necesidad de implementar otros comportamientos comunes en aplicaciones actuales:
-
Rastrear el estado de carga para mostrar indicadores de actividad (spinners) en la UI
-
Evitar solicitudes duplicadas para los mismos datos
-
Actualizaciones optimistas para que la UI se sienta más rápida
-
Gestionar el tiempo de vida de la caché según el usuario interactúa con la UI
Ya hemos visto cómo implementar estos comportamientos usando Redux Toolkit.
Sin embargo, originalmente Redux no incluía nada integrado para ayudar a resolver completamente estos casos de uso. Incluso cuando usamos createAsyncThunk junto con createSlice, sigue habiendo una cantidad considerable de trabajo manual involucrado en realizar solicitudes y gestionar el estado de carga. Debemos crear el thunk asíncrono, hacer la solicitud real, extraer campos relevantes de la respuesta, añadir campos de estado de carga, agregar manejadores en extraReducers para los casos pending/fulfilled/rejected, y escribir realmente las actualizaciones de estado adecuadas.
Con el tiempo, la comunidad de React ha comprendido que "la obtención de datos y el almacenamiento en caché" son realmente un conjunto de preocupaciones diferente a la "gestión del estado". Aunque puedes usar una biblioteca de gestión de estado como Redux para almacenar datos en caché, los casos de uso son lo suficientemente distintos como para justificar el uso de herramientas diseñadas específicamente para la obtención de datos.
Retos del estado del servidor
Vale la pena citar la gran explicación de la página de documentación "Motivación" de React Query:
Si bien la mayoría de las bibliotecas tradicionales de gestión de estado son excelentes para trabajar con estado del cliente, no son tan efectivas con el estado asíncrono o del servidor. Esto se debe a que el estado del servidor es completamente diferente. Para empezar, el estado del servidor:
- Se persiste de forma remota en una ubicación que puede que no controles o poseas
- Requiere APIs asíncronas para su obtención y actualización
- Implica propiedad compartida y puede ser modificado por otros sin tu conocimiento
- Puede volverse "obsoleto" en tus aplicaciones si no tienes cuidado
Una vez que comprendes la naturaleza del estado del servidor en tu aplicación, surgirán más retos adicionales, como:
- Almacenamiento en caché... (posiblemente lo más difícil en programación)
- Eliminar duplicados de múltiples solicitudes para los mismos datos consolidándolas en una sola
- Actualizar datos "obsoletos" en segundo plano
- Determinar cuándo los datos están "obsoletos"
- Reflejar actualizaciones de datos lo más rápido posible
- Optimizaciones de rendimiento como paginación y carga diferida de datos
- Gestión de memoria y recolección de basura del estado del servidor
- Memoización de resultados de consultas con compartición estructural
Diferencias de RTK Query
RTK Query se inspira en otras herramientas pioneras en obtención de datos como Apollo Client, React Query, Urql y SWR, pero añade un enfoque único en su diseño de API:
-
La lógica de obtención de datos y caché se construye sobre las APIs
createSliceycreateAsyncThunkde Redux Toolkit -
Al ser Redux Toolkit agnóstico a la interfaz de usuario, RTK Query funciona con cualquier capa de UI como Angular, Vue o vanilla JS, no solo con React
-
Los endpoints API se definen previamente, incluyendo cómo generar parámetros de consulta desde argumentos y transformar respuestas para almacenamiento en caché
-
RTK Query puede generar hooks de React que encapsulan todo el proceso de obtención de datos, proporcionan campos
dataeisFetchinga los componentes, y gestionan el ciclo de vida de los datos en caché según se montan y desmontan los componentes -
RTK Query ofrece opciones de "ciclo de vida de entrada en caché" que habilitan casos de uso como actualizaciones en tiempo real mediante websockets tras la obtención inicial de datos
-
Disponemos de un generador de código para crear definiciones de API RTK Query a partir de esquemas OpenAPI
-
Finalmente, RTK Query está completamente escrito en TypeScript y diseñado para ofrecer una excelente experiencia de uso con TS
Qué incluye
APIs
RTK Query está incluido en la instalación del paquete principal de Redux Toolkit. Está disponible a través de cualquiera de estos puntos de entrada:
// UI-agnostic entry point with the core logic
import { createApi } from '@reduxjs/toolkit/query'
// React-specific entry point that automatically generates
// hooks corresponding to the defined endpoints
import { createApi } from '@reduxjs/toolkit/query/react'
RTK Query consta principalmente de dos APIs:
createApi(): El núcleo de la funcionalidad de RTK Query. Te permite definir un conjunto de endpoints que describen cómo obtener datos de una serie de puntos de acceso, incluyendo la configuración de cómo obtener y transformar esos datos. En la mayoría de los casos, deberías usarlo una vez por aplicación, siguiendo la regla general de "una porción de API por URL base".
fetchBaseQuery(): Un envoltorio ligero sobrefetchque simplifica solicitudes HTTP. RTK Query puede almacenar en caché resultados de cualquier solicitud asíncrona, pero como las peticiones HTTP son el caso más común,fetchBaseQueryofrece soporte HTTP listo para usar.
Tamaño del paquete
RTK Query añade un tamaño fijo único al paquete de tu aplicación. Dado que RTK Query se construye sobre Redux Toolkit y React-Redux, el tamaño adicional varía dependiendo de si ya usas estas bibliotecas. Los tamaños estimados min+gzip son:
-
Si ya usas RTK: ~9kB para RTK Query y ~2kB para los hooks.
-
Si no usas RTK actualmente:
- Sin React: 17 kB para RTK + dependencias + RTK Query
- Con React: 19kB + React-Redux (dependencia externa)
Añadir definiciones de endpoints adicionales solo debería aumentar el tamaño según el código real dentro de las definiciones endpoints, que normalmente será de solo unos pocos bytes.
La funcionalidad incluida en RTK Query compensa rápidamente el tamaño añadido, y la eliminación de la lógica manual de obtención de datos debería suponer una mejora neta de tamaño en la mayoría de aplicaciones significativas.
Pensando en el almacenamiento en caché de RTK Query
Redux siempre ha hecho hincapié en la previsibilidad y el comportamiento explícito. No hay "magia" en Redux: deberías poder entender qué sucede en la aplicación porque toda la lógica de Redux sigue los mismos patrones básicos de despachar acciones y actualizar el estado mediante reductores. Esto significa que a veces hay que escribir más código para lograr resultados, pero la contrapartida es que el flujo de datos y el comportamiento deben estar muy claros.
Las API principales de Redux Toolkit no cambian el flujo básico de datos en una app Redux. Sigues despachando acciones y escribiendo reductores, solo que con menos código que escribiendo toda esa lógica manualmente. RTK Query funciona igual. Es un nivel adicional de abstracción, pero internamente sigue realizando exactamente los mismos pasos que ya hemos visto para gestionar solicitudes asíncronas y sus respuestas: usa thunks para ejecutar solicitudes asíncronas, despacha acciones con los resultados y gestiona esas acciones en reductores para almacenar en caché los datos.
Sin embargo, al usar RTK Query, sí ocurre un cambio de mentalidad. Ya no pensamos en "gestionar estado" per se. En su lugar, ahora pensamos en "gestionar datos en caché". En lugar de intentar escribir reductores nosotros mismos, ahora nos centramos en definir "¿de dónde vienen estos datos?", "¿cómo debe enviarse esta actualización?", "¿cuándo deben reobtenerse estos datos en caché?" y "¿cómo deben actualizarse los datos en caché?". Cómo se obtienen, almacenan y recuperan esos datos se convierte en detalles de implementación que ya no nos preocupan.
Veremos cómo se aplica este cambio de mentalidad a medida que continuemos.
Configuración de RTK Query
Nuestra aplicación de ejemplo ya funciona, pero ahora es momento de migrar toda la lógica asíncrona a RTK Query. A medida que avancemos, veremos cómo usar todas las características principales de RTK Query, además de cómo migrar usos existentes de createAsyncThunk y createSlice a las API de RTK Query.
Definición de un slice API
Anteriormente, definimos "slices" separados para cada tipo de datos: Posts, Usuarios y Notificaciones. Cada slice tenía su propio reductor, definía sus propias acciones y thunks, y almacenaba en caché las entradas de ese tipo de datos por separado.
Con RTK Query, la lógica para gestionar datos en caché se centraliza en un único "slice API" por aplicación. De la misma manera que tienes un único store Redux por app, ahora tenemos un único slice para todos nuestros datos en caché.
Comenzaremos definiendo un nuevo archivo apiSlice.ts. Como esto no es específico de ninguna otra "feature" que ya hayamos escrito, añadiremos una nueva carpeta features/api/ y pondremos apiSlice.ts dentro. Vamos a completar el archivo del slice API y luego desglosaremos el código para entender qué hace:
// Import the RTK Query methods from the React-specific entry point
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
// Use the `Post` type we've already defined in `postsSlice`,
// and then re-export it for ease of use
import type { Post } from '@/features/posts/postsSlice'
export type { Post }
// Define our single API slice object
export const apiSlice = createApi({
// The cache reducer expects to be added at `state.api` (already default - this is optional)
reducerPath: 'api',
// All of our requests will have URLs starting with '/fakeApi'
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
// The "endpoints" represent operations and requests for this server
endpoints: builder => ({
// The `getPosts` endpoint is a "query" operation that returns data.
// The return value is a `Post[]` array, and it takes no arguments.
getPosts: builder.query<Post[], void>({
// The URL for the request is '/fakeApi/posts'
query: () => '/posts'
})
})
})
// Export the auto-generated hook for the `getPosts` query endpoint
export const { useGetPostsQuery } = apiSlice
La funcionalidad de RTK Query se basa en un único método llamado createApi. Todas las API de Redux Toolkit que hemos visto hasta ahora son agnósticas a la interfaz de usuario y podrían usarse con cualquier capa de UI. La lógica central de RTK Query sigue el mismo principio. Sin embargo, RTK Query incluye una versión específica para React de createApi, y como estamos usando RTK junto con React, necesitamos importarla específicamente desde '@reduxjs/toolkit/query/react' para aprovechar la integración con React.
Se espera que tu aplicación tenga solo una llamada a createApi. Este único segmento de API debe contener todos los endpoints que se comuniquen con la misma URL base. Por ejemplo, endpoints como /api/posts y /api/users que obtienen datos del mismo servidor deben ir en el mismo segmento de API. Si tu aplicación obtiene datos de múltiples servidores, puedes especificar URLs completas en cada endpoint o, si es absolutamente necesario, crear segmentos de API separados para cada servidor.
Los endpoints normalmente se definen directamente dentro de la llamada a createApi. Si necesitas dividir tus endpoints entre varios archivos, consulta la sección «Inyectar endpoints» en la Parte 8 de la documentación.
Parámetros del Segmento de API
Al llamar a createApi, hay dos campos obligatorios:
-
baseQuery: función que sabe cómo obtener datos del servidor. RTK Query incluyefetchBaseQuery, un pequeño wrapper sobre la función estándarfetch()que maneja el procesamiento típico de solicitudes y respuestas HTTP. Al crear una instancia defetchBaseQuery, podemos pasar la URL base para todas las solicitudes futuras, así como personalizar comportamientos como modificar cabeceras de solicitud. Puedes crear base queries personalizadas para personalizar aspectos como el manejo de errores o autenticación. -
endpoints: conjunto de operaciones definidas para interactuar con este servidor. Los endpoints pueden ser queries (que devuelven datos para almacenar en caché) o mutations (que envían actualizaciones al servidor). Se definen mediante una función callback que recibe un parámetrobuildery devuelve un objeto con definiciones de endpoints creadas conbuilder.query()ybuilder.mutation().
createApi también acepta un campo reducerPath que define dónde se almacenará el estado de la caché en el estado global de Redux. Para otros slices como postsSlice, no hay garantía de que actualice state.posts (podríamos haber adjuntado el reducer en cualquier lugar del estado raíz, como someOtherField: postsReducer). Aquí, createApi espera que le indiquemos dónde existirá el estado de la caché cuando agreguemos el reducer al store. Si no se proporciona reducerPath, por defecto será 'api', por lo que todos los datos de caché de RTKQ se almacenarán bajo state.api.
Si olvidas agregar el reducer al store o lo adjuntas bajo una clave diferente a la especificada en reducerPath, RTKQ registrará un error para indicarte que debes corregirlo.
Definición de Endpoints
La primera parte de la URL para todas las solicitudes se define como '/fakeApi' en la definición de fetchBaseQuery.
Como primer paso, queremos agregar un endpoint que devuelva la lista completa de posts desde el servidor API simulado. Incluiremos un endpoint llamado getPosts y lo definiremos como un endpoint de query usando builder.query(). Este método acepta múltiples opciones para configurar cómo realizar la solicitud y procesar la respuesta. Por ahora, solo necesitamos proporcionar la parte restante de la ruta URL definiendo una opción query con un callback que devuelva la cadena de la URL: () => '/posts'.
Por defecto, los endpoints de consulta usarán una petición HTTP GET, pero puedes personalizarlo devolviendo un objeto como {url: '/posts', method: 'POST', body: newPost} en lugar de solo la cadena de la URL. También puedes definir varias opciones adicionales para la petición de esta manera, como establecer cabeceras.
Para uso con TypeScript, las funciones de definición de endpoints builder.query() y builder.mutation() aceptan dos argumentos genéricos: <ReturnType, ArgumentType>. Por ejemplo, un endpoint para obtener un Pokémon por nombre podría verse como getPokemonByName: builder.query<Pokemon, string>(). Si un endpoint no recibe argumentos, usa el tipo void, como en getAllPokemon: builder.query<Pokemon[], void>().
Exportación de API Slices y Hooks
En nuestras funciones createSlice anteriores, solo necesitábamos exportar los action creators y los slice reducers, porque eran las únicas partes de las funciones de slice necesarias en otros archivos. Con RTK Query, normalmente exportamos el objeto completo de 'API slice' porque contiene varios campos que pueden resultar útiles.
Finalmente, observa detenidamente la última línea de este archivo. ¿De dónde viene este valor useGetPostsQuery?
¡La integración de RTK Query con React generará automáticamente hooks de React para cada endpoint que definamos! Estos hooks encapsulan el proceso de lanzar una petición cuando un componente se monta, y volver a renderizar el componente a medida que la petición se procesa y los datos están disponibles. Podemos exportar esos hooks desde este archivo de API slice para usarlos en nuestros componentes de React.
Los hooks se nombran automáticamente siguiendo una convención estándar:
-
use, el prefijo habitual para cualquier hook de React -
El nombre del endpoint, capitalizado
-
El tipo de endpoint,
QueryoMutation
En este caso, nuestro endpoint es getPosts y es una consulta, por lo que el hook generado es useGetPostsQuery.
Configuración del Store
Ahora necesitamos conectar el API slice a nuestro store de Redux. Podemos modificar el archivo store.ts existente para añadir el reductor de caché del API slice al estado. Además, el API slice genera un middleware personalizado que debe añadirse al store. Este middleware debe incluirse también: gestiona la caducidad y expiración de la caché.
import { configureStore } from '@reduxjs/toolkit'
import { apiSlice } from '@/features/api/apiSlice'
import authReducer from '@/features/auth/authSlice'
import postsReducer from '@/features/posts/postsSlice'
import usersReducer from '@/features/users/usersSlice'
import notificationsReducer from '@/features/notifications/notificationsSlice'
import { listenerMiddleware } from './listenerMiddleware'
export const store = configureStore({
// Pass in the root reducer setup as the `reducer` argument
reducer: {
auth: authReducer,
posts: postsReducer,
users: usersReducer,
notifications: notificationsReducer,
[apiSlice.reducerPath]: apiSlice.reducer
},
middleware: getDefaultMiddleware =>
getDefaultMiddleware()
.prepend(listenerMiddleware.middleware)
.concat(apiSlice.middleware)
})
Podemos reutilizar el campo apiSlice.reducerPath como clave computada en el parámetro reducer, para asegurarnos de que el reductor de caché se añade en el lugar correcto.
Como vimos cuando añadimos el middleware de escucha, debemos mantener todo el middleware estándar existente como redux-thunk en la configuración del store, y el middleware del API slice normalmente va después de estos. Ya estamos llamando a getDefaultMiddleware() y colocando el middleware de escucha al principio, así que podemos llamar a .concat(apiSlice.middleware) para añadirlo al final.
Visualización de Posts con Consultas
Uso de Hooks de Consulta en Componentes
Ahora que tenemos el API slice definido y añadido al store, podemos importar el hook generado useGetPostsQuery en nuestro componente <PostsList> y usarlo allí.
Actualmente, <PostsList> importa específicamente useSelector, useDispatch y useEffect, lee datos de posts y estado de carga del store, y despacha el thunk fetchPosts() al montarse para activar la obtención de datos. ¡El useGetPostsQueryHook reemplaza todo eso!
Veamos cómo se ve <PostsList> cuando usamos este hook:
import React from 'react'
import { Link } from 'react-router-dom'
import { Spinner } from '@/components/Spinner'
import { TimeAgo } from '@/components/TimeAgo'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
import { PostAuthor } from './PostAuthor'
import { ReactionButtons } from './ReactionButtons'
// Go back to passing a `post` object as a prop
interface PostExcerptProps {
post: Post
}
function PostExcerpt({ post }: PostExcerptProps) {
return (
<article className="post-excerpt" key={post.id}>
<h3>
<Link to={`/posts/${post.id}`}>{post.title}</Link>
</h3>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content.substring(0, 100)}</p>
<ReactionButtons post={post} />
</article>
)
}
export const PostsList = () => {
// Calling the `useGetPostsQuery()` hook automatically fetches data!
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
let content: React.ReactNode
// Show loading states based on the hook status flags
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = posts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
return (
<section className="posts-list">
<h2>Posts</h2>
{content}
</section>
)
}
Conceptualmente, <PostsList> sigue haciendo el mismo trabajo que antes, pero pudimos reemplazar las múltiples llamadas a useSelector y el despacho con useEffect por una única llamada a useGetPostsQuery().
(Nota que en este punto, la aplicación tendrá algunas discrepancias entre el código que aún busca datos en el segmento state.posts existente y el nuevo código que lee de RTK Query. Esto es normal, y corregiremos estas discrepancias una por una a medida que avancemos.)
Anteriormente, seleccionábamos una lista de IDs de publicaciones del almacén, pasábamos un ID de publicación a cada componente <PostExcerpt> y seleccionábamos cada objeto Post individual del almacén por separado. Como el array posts ya contiene todos los objetos de publicación, hemos vuelto a pasar los objetos de publicación directamente como props.
Normalmente deberías usar los hooks de consulta para acceder a datos en caché en componentes; no deberías escribir tus propias llamadas useSelector para acceder a datos obtenidos ni llamadas useEffect para activar la obtención.
Objetos de resultado de hooks de consulta
Cada hook de consulta generado devuelve un objeto "result" que contiene varios campos, entre ellos:
-
data: el contenido real de la respuesta del servidor para la entrada de caché exitosa más reciente. Este campo seráundefinedhasta que se reciba la respuesta. -
currentData: el contenido de la respuesta para los argumentos de consulta actuales. Puede cambiar aundefinedsi los argumentos de consulta cambian y se inicia una solicitud porque no existe una entrada de caché. -
isLoading: un booleano que indica si este hook está realizando la primera solicitud al servidor porque aún no hay datos. (Ten en cuenta que si los parámetros cambian para solicitar datos diferentes,isLoadingseguirá siendo falso.) -
isFetching: un booleano que indica si el hook está realizando cualquier solicitud al servidor -
isSuccess: un booleano que indica si el hook ha realizado una solicitud exitosa y tiene datos en caché disponibles (es decir,datadebería estar definido ahora) -
isError: un booleano que indica si la última solicitud tuvo un error -
error: un objeto de error serializado
Es común desestructurar campos del objeto de resultado, y posiblemente renombrar data a una variable más específica como posts para describir su contenido. Luego podemos usar los booleanos de estado y los campos data/error para renderizar la UI deseada. Sin embargo, si usas una versión antigua de TypeScript, quizá necesites mantener el objeto original y referirte a las banderas como result.isSuccess en tus comprobaciones condicionales, para que TS pueda inferir correctamente que data es válido.
Campos de estado de carga
Ten en cuenta que isLoading e isFetching son banderas diferentes con comportamientos distintos. Puedes decidir cuál usar según cuándo y cómo necesites mostrar estados de carga en la UI. Por ejemplo, quizá quieras comprobar isLoading para mostrar un esqueleto durante la primera carga de una página, o elegir isFetching para mostrar un spinner o atenuar resultados existentes cada vez que haya una solicitud mientras el usuario selecciona diferentes elementos.
De forma similar, data y currentData cambian en momentos distintos. Normalmente deberías usar los valores en data, pero currentData está disponible para darte mayor granularidad en el comportamiento de carga. Por ejemplo, si quisieras mostrar datos en la UI como translúcidos para representar un estado de recarga, puedes usar data combinado con isFetching, ya que data permanece igual hasta que la nueva solicitud finalice. Pero si también quieres mostrar solo valores correspondientes al argumento actual (como vaciar la UI hasta completar la nueva solicitud), puedes usar currentData para lograrlo.
Ordenar publicaciones
Desafortunadamente, las publicaciones ahora se muestran desordenadas. Anteriormente las ordenábamos por fecha a nivel del reducer con la opción de ordenación de createEntityAdapter. Como el segmento de API solo almacena en caché el array exacto devuelto por el servidor, no se aplica ninguna ordenación específica: el orden que el servidor devuelve es el que tenemos.
Existen varias opciones para manejar esto. Por ahora, realizaremos la ordenación dentro del propio <PostsList>, y más adelante hablaremos de las otras alternativas y sus contrapartidas.
No podemos simplemente llamar a posts.sort() directamente porque Array.sort() muta el array original, así que primero necesitamos hacer una copia. Para evitar reordenar en cada rerenderizado, podemos hacer la ordenación en un hook useMemo(). También queremos dar a posts un array vacío por defecto en caso de que sea undefined, para tener siempre un array que ordenar.
// omit setup
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
// Sort posts in descending chronological order
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = sortedPosts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
// omit rendering
}
Mostrar publicaciones individuales
Hemos actualizado <PostsList> para obtener una lista de todas las publicaciones y mostramos fragmentos de cada Post en la lista. Pero si hacemos clic en "Ver publicación" en cualquiera de ellas, nuestro componente <SinglePostPage> fallará al buscar una publicación en el antiguo slice state.posts y mostrará el error "¡Publicación no encontrada!". Necesitamos actualizar <SinglePostPage> para que también use RTK Query.
Hay un par de formas de hacerlo. Una sería que <SinglePostPage> llamara al mismo hook useGetPostsQuery(), obtuviera todo el array de publicaciones y encontrara exactamente el objeto Post que necesita mostrar. Los hooks de consulta también tienen la opción selectFromResult que nos permitiría hacer esa misma búsqueda antes, dentro del propio hook; lo veremos en acción más adelante.
En su lugar, vamos a intentar añadir otra definición de endpoint que nos permita solicitar una única publicación al servidor según su ID. Esto es algo redundante, pero nos permitirá ver cómo se puede usar RTK Query para personalizar solicitudes de consulta basadas en argumentos.
Añadir el endpoint de consulta para publicaciones individuales
En apiSlice.ts, vamos a añadir otra definición de endpoint de consulta llamada getPost (esta vez sin 's'):
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts'
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
})
})
})
export const { useGetPostsQuery, useGetPostQuery } = apiSlice
El endpoint getPost se parece mucho al existente getPosts, pero el parámetro query es diferente. Aquí, query toma un argumento llamado postId, y usamos ese postId para construir la URL del servidor. Así podemos hacer una solicitud al servidor para un único objeto Post específico.
Esto también genera un nuevo hook useGetPostQuery, así que lo exportamos también.
Argumentos de consulta y claves de caché
Nuestro <SinglePostPage> actualmente lee una entrada Post de state.posts según el ID. Necesitamos actualizarlo para que llame al nuevo hook useGetPostQuery y use estados de carga similares a los de la lista principal.
// omit some imports
import { useGetPostQuery } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export const SinglePostPage = () => {
const { postId } = useParams()
const currentUsername = useAppSelector(selectCurrentUsername)
const { data: post, isFetching, isSuccess } = useGetPostQuery(postId!)
let content: React.ReactNode
const canEdit = currentUsername === post?.user
if (isFetching) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = (
<article className="post">
<h2>{post.title}</h2>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content}</p>
<ReactionButtons post={post} />
{canEdit && (
<Link to={`/editPost/${post.id}`} className="button">
Edit Post
</Link>
)}
</article>
)
}
return <section>{content}</section>
}
Fíjate que estamos tomando el postId que hemos leído de la ruta del router y pasándolo como argumento a useGetPostQuery. El hook de consulta usará eso para construir la URL de solicitud y obtener este objeto Post específico.
Entonces, ¿cómo se está almacenando en caché toda esta información? Hagamos clic en "Ver publicación" para una de nuestras entradas y luego veamos qué hay dentro del store de Redux en este momento.
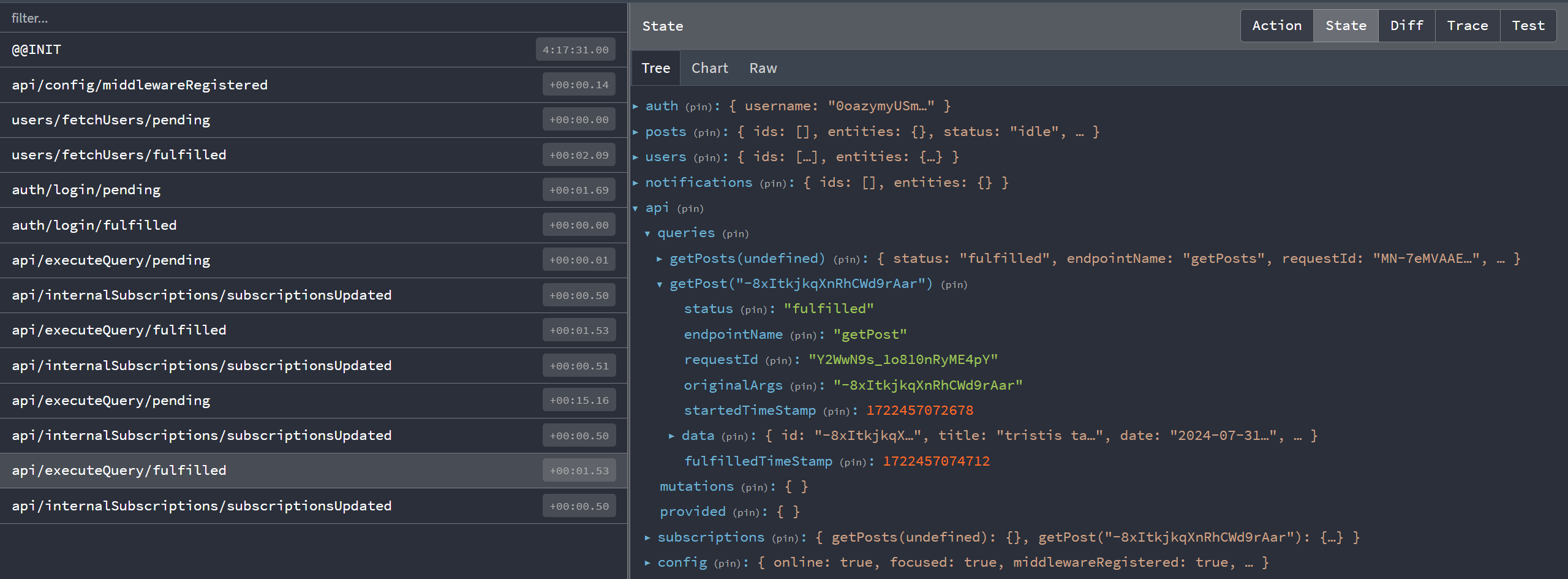
Podemos ver que tenemos un slice de nivel superior state.api, como esperábamos por la configuración del store. Dentro hay una sección llamada queries que actualmente tiene dos elementos. La clave getPosts(undefined) representa los metadatos y contenidos de respuesta para la solicitud que hicimos con el endpoint getPosts. De manera similar, la clave getPost('abcd1234') es para la solicitud específica que acabamos de hacer para esta publicación.
RTK Query crea una "clave de caché" para cada combinación única de endpoint + argumentos, y almacena los resultados para cada clave de caché por separado. Esto significa que puedes usar el mismo hook de consulta múltiples veces, pasarle diferentes parámetros de consulta, y cada resultado se almacenará en caché por separado en el store de Redux.
Si necesitas los mismos datos en varios componentes, ¡simplemente llama al mismo hook de consulta con los mismos argumentos en cada componente! Por ejemplo, puedes llamar a useGetPostQuery('123') en tres componentes diferentes y RTK Query se encargará de que los datos solo se obtengan una vez, mientras cada componente se vuelve a renderizar según sea necesario.
También es importante destacar que ¡el parámetro de consulta debe ser un único valor! Si necesitas pasar múltiples parámetros, debes usar un objeto con varios campos (exactamente igual que con createAsyncThunk). RTK Query realizará una comparación "superficial estable" de los campos y volverá a obtener los datos si alguno cambia.
Observa que los nombres de las acciones en la lista izquierda son más genéricos y menos descriptivos: api/executeQuery/fulfilled, en lugar de posts/fetchPosts/fulfilled. Esto es un equilibrio inherente al usar una capa de abstracción adicional. Las acciones individuales sí contienen el nombre del endpoint específico en action.meta.arg.endpointName, pero no es tan visible en el historial de acciones.
Las Redux DevTools incluyen una pestaña "RTK Query" que muestra los datos de RTK Query en un formato más útil, centrado en entradas de caché en lugar de la estructura de estado bruta de Redux. Esto incluye información sobre cada endpoint y resultado en caché, estadísticas de tiempo de consulta y mucho más:
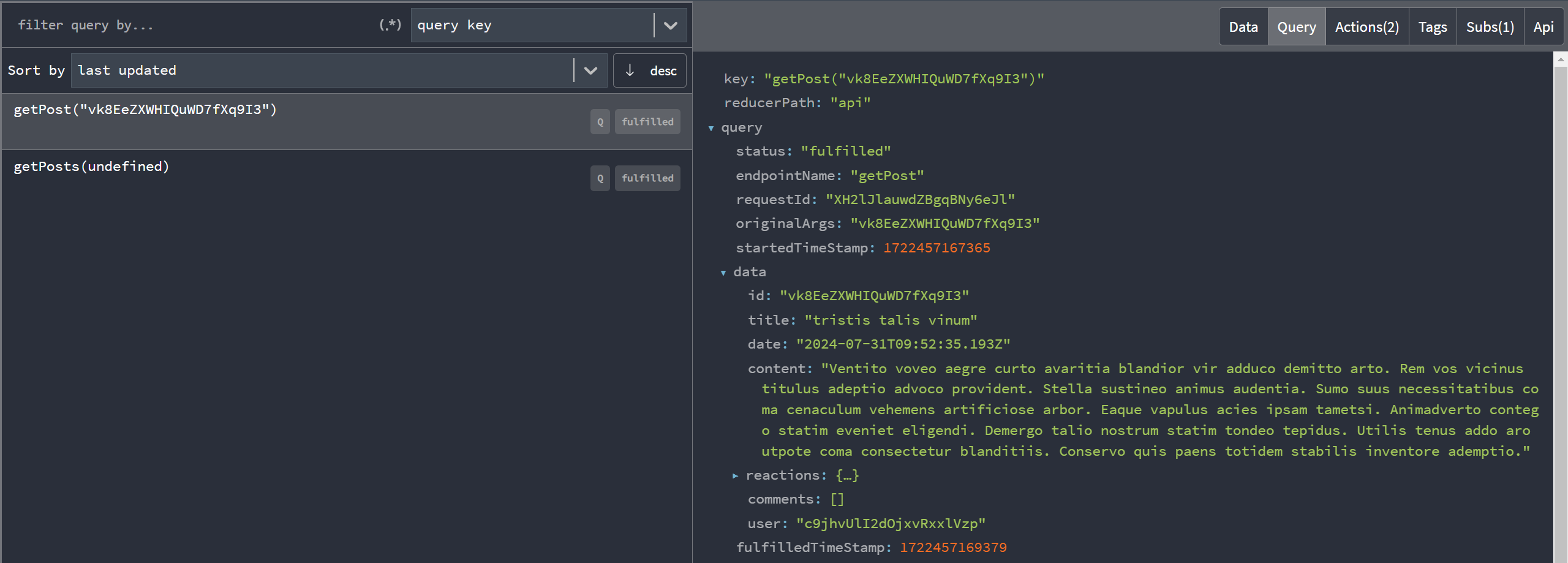
También puedes ver esta demo en vivo de las devtools de RTK Query:
Creación de entradas con mutaciones
Hemos visto cómo obtener datos del servidor definiendo endpoints de "consulta", pero ¿y si necesitamos enviar actualizaciones al servidor?
RTK Query permite definir endpoints de mutación que actualizan datos en el servidor. Añadamos una mutación que nos permita agregar una nueva entrada.
Añadiendo el endpoint de mutación para nuevas entradas
Añadir un endpoint de mutación es muy similar a añadir uno de consulta. La principal diferencia es que definimos el endpoint con builder.mutation() en lugar de builder.query(). Además, debemos cambiar el método HTTP a 'POST' y proporcionar el cuerpo de la solicitud.
Exportaremos el tipo TypeScript NewPost existente desde postsSlice.ts y lo usaremos como tipo de argumento en esta mutación, ya que es lo que nuestro componente necesita pasar.
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
import type { Post, NewPost } from '@/features/posts/postsSlice'
export type { Post }
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts'
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
// The HTTP URL will be '/fakeApi/posts'
url: '/posts',
// This is an HTTP POST request, sending an update
method: 'POST',
// Include the entire post object as the body of the request
body: initialPost
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation
} = apiSlice
Como con los endpoints de consulta, especificamos los tipos de TypeScript: la mutación devuelve un Post completo y acepta el valor parcial NewPost como argumento.
Aquí nuestra opción query devuelve un objeto con {url, method, body}, lo que nos permite especificar que será una solicitud HTTP POST y definir el contenido del body. Como usamos fetchBaseQuery para las solicitudes, el campo body se serializará automáticamente en JSON. (Y sí, la palabra "post" aparece demasiadas veces en este ejemplo 😉)
Al igual que con los endpoints de consulta, el slice de API genera automáticamente un hook de React para el endpoint de mutación: en este caso, useAddNewPostMutation.
Uso de hooks de mutación en componentes
Nuestro <AddPostForm> ya despacha un thunk asíncrono para añadir una entrada al hacer clic en "Guardar entrada". Para ello, importa useDispatch y el thunk addNewPost. Los hooks de mutación reemplazan ambos, con un patrón de uso similar:
import React from 'react'
import { useAppSelector } from '@/app/hooks'
import { useAddNewPostMutation } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
// omit field types
export const AddPostForm = () => {
const userId = useAppSelector(selectCurrentUsername)!
const [addNewPost, { isLoading }] = useAddNewPostMutation()
const handleSubmit = async (e: React.FormEvent<AddPostFormElements>) => {
// Prevent server submission
e.preventDefault()
const { elements } = e.currentTarget
const title = elements.postTitle.value
const content = elements.postContent.value
const form = e.currentTarget
try {
await addNewPost({ title, content, user: userId }).unwrap()
form.reset()
} catch (err) {
console.error('Failed to save the post: ', err)
}
}
return (
<section>
<h2>Add a New Post</h2>
<form onSubmit={handleSubmit}>
<label htmlFor="postTitle">Post Title:</label>
<input
type="text"
id="postTitle"
name="postTitle"
defaultValue=""
required
/>
<label htmlFor="postContent">Content:</label>
<textarea
id="postContent"
name="postContent"
defaultValue=""
required
/>
<button disabled={isLoading}>Save Post</button>
</form>
</section>
)
}
Los hooks de mutación devuelven un array con dos valores:
-
El primer valor es una "función disparadora". Al llamarla, realiza la solicitud al servidor con el argumento que proporciones. Es un thunk ya encapsulado para despacharse inmediatamente.
-
El segundo valor es un objeto con metadatos sobre la solicitud en curso, si existe. Incluye una bandera
isLoadingque indica si hay una solicitud en progreso.
Podemos reemplazar el envío del thunk existente y el estado de carga del componente con la función de activación y la bandera isLoading del hook useAddNewPostMutation, mientras el resto del componente permanece igual.
Al igual que con el envío del thunk anterior, llamamos a addNewPost con el objeto de publicación inicial. Esto devuelve una Promise especial con un método .unwrap(), y podemos usar await addNewPost().unwrap() para manejar posibles errores con un bloque try/catch estándar. (Esto se ve igual que lo que vimos con createAsyncThunk, porque es lo mismo: RTK Query usa internamente createAsyncThunk)
Actualización de datos en caché
Cuando hacemos clic en "Guardar publicación", podemos ver la pestaña Network en las DevTools del navegador y confirmar que la solicitud HTTP POST se realizó correctamente. Pero la nueva publicación no aparece en nuestra <PostsList> si volvemos allí. El estado del store de Redux no ha cambiado y seguimos teniendo los mismos datos en caché en memoria.
Necesitamos indicar a RTK Query que actualice su lista de publicaciones en caché para que podamos ver la nueva publicación que acabamos de añadir.
Volver a solicitar publicaciones manualmente
La primera opción es forzar manualmente a RTK Query a que vuelva a solicitar los datos para un endpoint determinado. Este no es el enfoque que usarías en una aplicación real, pero lo probaremos ahora como un paso intermedio.
Los objetos de resultado del hook de consulta incluyen una función refetch que podemos llamar para forzar una nueva solicitud. Podemos añadir temporalmente un botón "Volver a solicitar publicaciones" a <PostsList> y hacer clic en él después de añadir una nueva publicación:
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error,
refetch
} = useGetPostsQuery()
// omit content
return (
<section className="posts-list">
<h2>Posts</h2>
<button onClick={refetch}>Refetch Posts</button>
{content}
</section>
)
}
Ahora, si añadimos una nueva publicación, esperamos a que se complete y hacemos clic en "Volver a solicitar publicaciones", deberíamos ver que aparece la nueva publicación.
Desafortunadamente, no hay un indicador real de que se esté realizando la nueva solicitud. Sería útil mostrar algo que indique que la solicitud de nueva obtención de datos está en curso.
Anteriormente vimos que los hooks de consulta tienen una bandera isLoading, que es true si es la primera solicitud de datos, y una bandera isFetching, que es true mientras cualquier solicitud de datos está en curso. Podríamos mirar la bandera isFetching y reemplazar toda la lista de publicaciones con un spinner de carga nuevamente mientras se realiza la nueva solicitud. Pero eso podría ser un poco molesto, y además, ya tenemos todas estas publicaciones, ¿por qué deberíamos ocultarlas por completo?
En su lugar, podríamos hacer que la lista existente de publicaciones sea parcialmente transparente para indicar que los datos están obsoletos, pero mantenerlos visibles mientras se realiza la nueva solicitud. Tan pronto como se complete la solicitud, podemos volver a mostrar la lista de publicaciones con normalidad.
import classnames from 'classnames'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
// omit other imports and PostExcerpt
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isFetching,
isSuccess,
isError,
error,
refetch
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content: React.ReactNode
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
const renderedPosts = sortedPosts.map(post => (
<PostExcerpt key={post.id} post={post} />
))
const containerClassname = classnames('posts-container', {
disabled: isFetching
})
content = <div className={containerClassname}>{renderedPosts}</div>
} else if (isError) {
content = <div>{error.toString()}</div>
}
// omit return
}
Si añadimos una nueva publicación y luego hacemos clic en "Volver a solicitar publicaciones", ahora deberíamos ver que la lista de publicaciones se vuelve semitransparente durante un par de segundos y luego se vuelve a renderizar con la nueva publicación añadida en la parte superior.
Actualización automática mediante invalidación de la caché
Forzar manualmente una nueva solicitud de datos es necesario ocasionalmente según el comportamiento del usuario, pero definitivamente no es una buena solución para un uso normal.
Sabemos que nuestro "servidor" tiene una lista completa de todas las publicaciones, incluida la que acabamos de añadir. Idealmente, queremos que nuestra aplicación vuelva a solicitar automáticamente la lista actualizada de publicaciones tan pronto como se complete la solicitud de mutación. De esta manera, sabemos que nuestros datos en caché del lado del cliente están sincronizados con lo que tiene el servidor.
RTK Query nos permite definir relaciones entre consultas y mutaciones para permitir la nueva solicitud automática de datos, usando "etiquetas" (tags). Una "etiqueta" es una cadena o un objeto pequeño que te permite dar identificadores a ciertos tipos de datos e "invalidar" partes de la caché. Cuando una etiqueta de caché se invalida, RTK Query volverá a solicitar automáticamente los endpoints que estaban marcados con esa etiqueta.
El uso básico de etiquetas requiere añadir tres piezas de información a nuestro segmento de API:
-
Un campo raíz
tagTypesen el objeto del segmento de API, que declara un array de nombres de etiquetas de cadena para tipos de datos como'Post' -
Un array
providesTagsen endpoints de consulta, que enumera un conjunto de etiquetas que describen los datos en esa consulta -
Un array
invalidatesTagsen endpoints de mutación, que enumera un conjunto de etiquetas que se invalidan cada vez que se ejecuta esa mutación
Podemos añadir una única etiqueta llamada 'Post' a nuestro slice API que nos permitirá reobtener automáticamente nuestro endpoint getPosts cada vez que añadamos una nueva publicación:
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
})
})
})
¡Eso es todo lo necesario! Ahora, si hacemos clic en "Guardar publicación", verás que el componente <PostsList> se atenuará automáticamente después de unos segundos, y luego se volverá a renderizar con la nueva publicación añadida al principio.
Nota que no hay nada especial en el texto literal 'Post'. Podríamos haberlo llamado 'Fred', 'qwerty' o cualquier otra cosa. Solo necesita ser la misma cadena en cada campo, para que RTK Query sepa: "cuando ocurra esta mutación, invalida todos los endpoints que tengan esa misma cadena de etiqueta".
Lo que has aprendido
- RTK Query es una solución de obtención y almacenamiento en caché incluida en Redux Toolkit
- RTK Query abstrae la gestión de datos del servidor en caché, eliminando la necesidad de escribir lógica para estados de carga, almacenamiento de resultados y realización de peticiones
- RTK Query se basa en los mismos patrones usados en Redux, como thunks asíncronos
- RTK Query usa un único "slice API" por aplicación, definido con createApi
- RTK Query ofrece versiones independientes de la UI y específicas para React de createApi
- Los slices API definen múltiples "endpoints" para diferentes operaciones del servidor
- El slice API incluye hooks de React auto-generados cuando se usa la integración con React
- Los endpoints de consulta permiten obtener y almacenar en caché datos del servidor
- Los hooks de consulta devuelven un valor data junto con indicadores de estado de carga
- Las consultas pueden reobtenerse manualmente o automáticamente usando "etiquetas" para invalidación de caché
- Los endpoints de mutación permiten actualizar datos en el servidor
- Los hooks de mutación devuelven una función "trigger" que envía solicitudes de actualización, junto con indicadores de estado
- La función trigger devuelve una Promise que puede "desenvolverse" y esperarse con await
- RTK Query es una solución de obtención de datos y almacenamiento en caché incluida en Redux Toolkit
- RTK Query abstrae el proceso de gestionar datos del servidor en caché por ti, eliminando la necesidad de escribir lógica para estado de carga, almacenar resultados y realizar solicitudes
- RTK Query se construye sobre los mismos patrones usados en Redux, como thunks asíncronos
- RTK Query usa una única "API slice" por aplicación, definida usando
createApi- RTK Query proporciona versiones independientes de la UI y específicas para React de
createApi - Las API slices definen múltiples "endpoints" para diferentes operaciones del servidor
- La API slice incluye React hooks auto-generados si se usa la integración con React
- RTK Query proporciona versiones independientes de la UI y específicas para React de
- Los endpoints de query permiten obtener y almacenar en caché datos del servidor
- Los hooks de query devuelven un valor
data, además de flags de estado de carga - La query se puede volver a obtener manualmente o automáticamente usando "tags" para invalidación de caché
- Los hooks de query devuelven un valor
- Los endpoints de mutation permiten actualizar datos en el servidor
- Los hooks de mutation devuelven una función "trigger" que envía solicitudes de actualización, además del estado de carga
- La función trigger devuelve una Promise que puede ser "unwrapped" y esperada
¿Qué sigue?
RTK Query ofrece un comportamiento predeterminado sólido, pero también incluye muchas opciones para personalizar cómo se gestionan las solicitudes y cómo trabajar con datos en caché. En Parte 8: Patrones avanzados de RTK Query, veremos cómo usar estas opciones para implementar funciones útiles como actualizaciones optimistas.