Redux Essentials, Parte 8: Patrones Avanzados de RTK Query
Esta página fue traducida por PageTurner AI (beta). No está respaldada oficialmente por el proyecto. ¿Encontraste un error? Reportar problema →
- Cómo usar etiquetas con IDs para gestionar la invalidación de caché y recarga de datos
- Cómo trabajar con la caché de RTK Query fuera de React
- Técnicas para manipular datos de respuesta
- Implementar actualizaciones optimistas y actualizaciones en streaming
- Completar la Parte 7 para entender configuración y uso básico de RTK Query
Introducción
En la Parte 7: Conceptos Básicos de RTK Query, vimos cómo configurar y usar la API de RTK Query para manejar la obtención de datos y almacenamiento en caché en nuestra aplicación. Añadimos un "segmento de API" a nuestro almacén de Redux, definimos puntos finales de "consulta" para obtener datos de publicaciones y un punto final de "mutación" para añadir nuevas publicaciones.
En esta sección, continuaremos migrando nuestra aplicación de ejemplo para usar RTK Query con otros tipos de datos, y veremos cómo utilizar algunas de sus funciones avanzadas para simplificar la base de código y mejorar la experiencia de usuario.
Algunos cambios en esta sección no son estrictamente necesarios; se incluyen para demostrar las características de RTK Query y mostrar algunas cosas que puedes hacer, para que veas cómo usar estas funciones si las necesitas.
Editar publicaciones
Ya hemos añadido un punto final de mutación para guardar nuevas publicaciones en el servidor, usado en nuestro <AddPostForm>. Ahora necesitamos actualizar el <EditPostForm> para permitir editar publicaciones existentes.
Actualizar el formulario de edición
Como al añadir publicaciones, el primer paso es definir un nuevo punto final de mutación en nuestro segmento de API. Será similar a la mutación para añadir publicaciones, pero debe incluir el ID de la publicación en la URL y usar una petición HTTP PATCH para indicar que actualiza algunos campos.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation<Post, PostUpdate>({
query: post => ({
url: `posts/${post.id}`,
method: 'PATCH',
body: post
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
Una vez añadido, podemos actualizar el <EditPostForm>. Necesita leer la entrada Post original del almacén, usarla para inicializar el estado del componente y editar los campos, luego enviar los cambios actualizados al servidor. Actualmente, leemos la entrada Post con selectPostById y despachamos manualmente un thunk postUpdated.
Podemos usar el mismo hook useGetPostQuery que en <SinglePostPage> para leer la entrada Post de la caché en el almacén, y usaremos el nuevo hook useEditPostMutation para guardar los cambios. Si queremos, también podemos añadir un spinner y deshabilitar los campos del formulario durante la actualización.
import React from 'react'
import { useNavigate, useParams } from 'react-router-dom'
import { Spinner } from '@/components/Spinner'
import { useGetPostQuery, useEditPostMutation } from '@/features/api/apiSlice'
// omit form types
export const EditPostForm = () => {
const { postId } = useParams()
const navigate = useNavigate()
const { data: post } = useGetPostQuery(postId!)
const [updatePost, { isLoading }] = useEditPostMutation()
if (!post) {
return (
<section>
<h2>Post not found!</h2>
</section>
)
}
const onSavePostClicked = async (
e: React.FormEvent<EditPostFormElements>
) => {
// Prevent server submission
e.preventDefault()
const { elements } = e.currentTarget
const title = elements.postTitle.value
const content = elements.postContent.value
if (title && content) {
await updatePost({ id: post.id, title, content })
navigate(`/posts/${postId}`)
}
}
// omit rendering
}
Duración de suscripciones a datos en caché
Probemos esto. Abre las DevTools de tu navegador, ve a la pestaña Network, actualiza la página, limpia la pestaña de red e inicia sesión. Verás una petición GET a /posts al obtener los datos iniciales. Al hacer clic en "Ver publicación", verás una segunda petición a /posts/:postId que devuelve esa publicación individual.
Ahora haz clic en "Editar publicación" dentro de la página de publicación. La interfaz cambia a <EditPostForm>, pero esta vez no hay petición de red para la publicación individual. ¿Por qué?

RTK Query permite que varios componentes se suscriban a los mismos datos y garantiza que cada conjunto único de datos solo se obtenga una vez. Internamente, RTK Query mantiene un contador de referencias de "suscripciones" activas para cada combinación de endpoint + clave de caché. Si el Componente A llama a useGetPostQuery(42), esos datos se obtendrán. Si luego el Componente B se monta y también llama a useGetPostQuery(42), está solicitando los mismos datos. Ya existe una entrada en la caché, así que no es necesario realizar una petición. Ambos usos del hook devolverán exactamente los mismos resultados, incluyendo los data obtenidos y los indicadores de estado de carga.
Cuando el número de suscripciones activas baja a cero, RTK Query inicia un temporizador interno. Si el temporizador expira antes de que se agregue cualquier nueva suscripción para esos datos, RTK Query eliminará esos datos de la caché automáticamente, porque la aplicación ya no los necesita. Sin embargo, si se agrega una nueva suscripción antes de que expire el temporizador, este se cancela y se utilizan los datos ya almacenados en caché sin necesidad de volver a obtenerlos.
En este caso, nuestra <SinglePostPage> se montó y solicitó ese Post individual por ID. Al hacer clic en "Edit Post", el componente <SinglePostPage> fue desmontado por el enrutador, eliminándose la suscripción activa debido al desmontaje. RTK Query inició inmediatamente un temporizador para "eliminar los datos de este post". Pero el componente <EditPostPage> se montó inmediatamente después y se suscribió a los mismos datos de Post con la misma clave de caché. Por lo tanto, RTK Query canceló el temporizador y mantuvo los mismos datos en caché en lugar de obtenerlos del servidor.
Por defecto, los datos no utilizados se eliminan de la caché después de 60 segundos, pero esto puede configurarse en la definición del slice de API raíz o sobrescribirse en definiciones de endpoints individuales usando la bandera keepUnusedDataFor, que especifica la duración en caché en segundos.
Invalidación de elementos específicos
Nuestro componente <EditPostForm> ahora puede guardar la publicación editada en el servidor, pero tenemos un problema. Si hacemos clic en "Save Post" durante la edición, volvemos a la <SinglePostPage>, pero aún muestra los datos antiguos sin las ediciones. La <SinglePostPage> sigue usando la entrada Post en caché obtenida anteriormente. Además, si volvemos a la página principal y miramos el <PostsList>, también muestra los datos antiguos. Necesitamos forzar una nueva obtención tanto de la entrada Post individual como de toda la lista de publicaciones.
Anteriormente vimos cómo usar "etiquetas" para invalidar partes de nuestros datos en caché. Declaramos que el endpoint de consulta getPosts proporciona una etiqueta 'Post', y que el endpoint de mutación addNewPost invalida esa misma etiqueta 'Post'. Así, cada vez que añadimos una nueva publicación, forzamos a RTK Query a volver a obtener toda la lista de publicaciones desde el endpoint getQuery.
Podríamos añadir una etiqueta 'Post' tanto a la consulta getPost como a la mutación editPost, pero eso forzaría a volver a obtener todas las demás publicaciones individuales. Afortunadamente, RTK Query permite definir etiquetas específicas para invalidar datos de forma más selectiva. Estas etiquetas específicas tienen formato {type: 'Post', id: 123}.
Nuestra consulta getPosts define un campo providesTags que es un array de cadenas. El campo providesTags también puede aceptar una función callback que recibe el result y arg, y devuelve un array. Esto nos permite crear entradas de etiquetas basadas en los IDs de los datos obtenidos. Del mismo modo, invalidatesTags también puede ser una callback.
Para lograr el comportamiento correcto, debemos configurar cada endpoint con las etiquetas adecuadas:
-
getPosts: proporciona una etiqueta general'Post'para toda la lista, además de una etiqueta específica{type: 'Post', id}para cada objeto de publicación recibido -
getPost: proporciona una etiqueta específica{type: 'Post', id}para el objeto de publicación individual -
addNewPost: invalida la etiqueta general'Post'para volver a obtener la lista completa -
editPost: invalida la etiqueta específica{type: 'Post', id}. Esto forzará una nueva obtención tanto de la publicación individual desdegetPost, como de la lista completa de publicaciones desdegetPosts, porque ambas proporcionan una etiqueta que coincide con ese valor{type, id}.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: (result = [], error, arg) => [
'Post',
...result.map(({ id }) => ({ type: 'Post', id }) as const)
]
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`,
providesTags: (result, error, arg) => [{ type: 'Post', id: arg }]
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation<Post, PostUpdate>({
query: post => ({
url: `posts/${post.id}`,
method: 'PATCH',
body: post
}),
invalidatesTags: (result, error, arg) => [{ type: 'Post', id: arg.id }]
})
})
})
Es posible que el argumento result en estas funciones de retorno sea undefined si la respuesta no tiene datos o hay un error, por lo que debemos manejarlo de forma segura. Para getPosts podemos hacerlo usando un valor de matriz predeterminado para iterar, y para getPost ya estamos devolviendo una matriz de un solo elemento basada en el ID del argumento. Para editPost, conocemos el ID de la publicación a partir del objeto parcial de publicación que se pasó a la función de activación, por lo que podemos leerlo desde allí.
Con estos cambios implementados, volvamos a intentar editar una publicación, con la pestaña Red abierta en las herramientas de desarrollo del navegador.
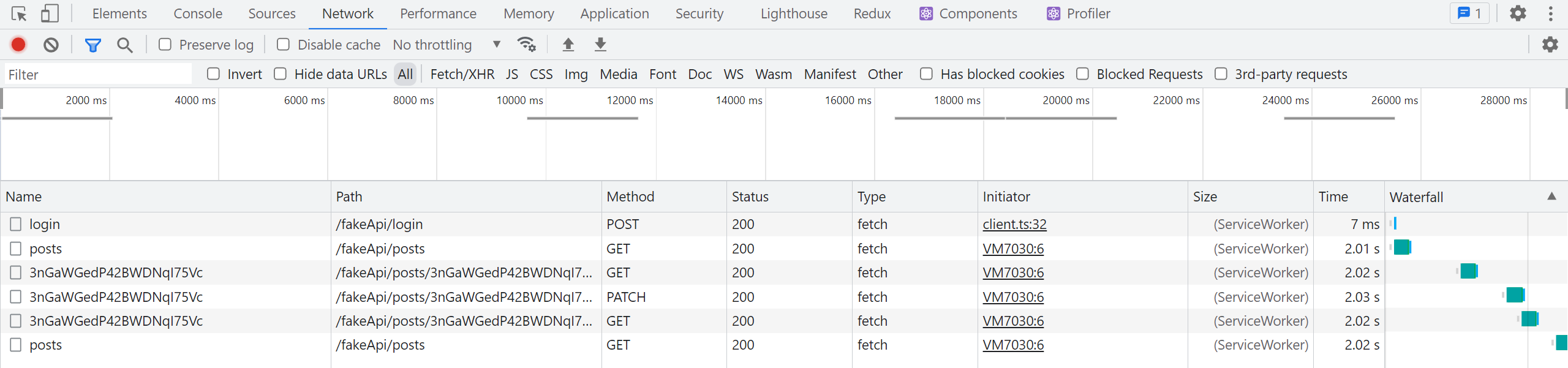
Cuando guardemos la publicación editada esta vez, deberíamos ver dos solicitudes consecutivas:
-
El
PATCH /posts/:postIdde la mutacióneditPost -
Un
GET /posts/:postIdmientras se vuelve a obtener la consultagetPost
Luego, si volvemos a la pestaña principal "Publicaciones", también deberíamos ver:
- Un
GET /postsmientras se vuelve a obtener la consultagetPosts
Como proporcionamos las relaciones entre los endpoints usando etiquetas, RTK Query supo que necesitaba volver a obtener la publicación individual y la lista de publicaciones cuando realizamos esa edición y se invalidó la etiqueta específica con ese ID, ¡sin necesidad de más cambios! Mientras tanto, mientras editábamos la publicación, expiró el temporizador de eliminación de caché para los datos de getPosts, por lo que se eliminaron de la caché. Cuando volvimos a abrir el componente <PostsList>, RTK Query vio que no tenía los datos en caché y los volvió a obtener.
Hay una salvedad aquí. Al especificar una etiqueta simple 'Post' en getPosts e invalidarla en addNewPost, terminamos forzando una nueva obtención de todas las publicaciones individuales también. Si realmente queremos volver a obtener solo la lista de publicaciones para el endpoint getPosts, puedes incluir una etiqueta adicional con un ID arbitrario, como {type: 'Post', id: 'LIST'}, e invalidar esa etiqueta en su lugar. La documentación de RTK Query tiene una tabla que describe lo que sucederá si se invalidan ciertas combinaciones de etiquetas generales/específicas.
RTK Query tiene muchas otras opciones para controlar cuándo y cómo volver a obtener datos, incluida la "obtención condicional", "consultas diferidas" y "precarga", y las definiciones de consulta se pueden personalizar de varias formas. Consulta la documentación de la guía de uso de RTK Query para obtener más detalles sobre estas características:
Actualización de las notificaciones emergentes
Cuando cambiamos de despachar thunks para agregar publicaciones a usar una mutación de RTK Query, rompimos accidentalmente el comportamiento del mensaje emergente "Nueva publicación agregada", porque la acción addNewPost.fulfilled ya no se está despachando.
Afortunadamente, esto es fácil de solucionar. RTK Query internamente utiliza createAsyncThunk, y ya hemos visto que despacha acciones de Redux mientras se realizan las solicitudes. Podemos actualizar el listener de notificaciones para observar las acciones internas de RTKQ y mostrar el mensaje emergente cuando ocurran.
createApi genera automáticamente thunks internos para cada endpoint. También genera automáticamente funciones "matcher" de RTK, que aceptan un objeto de acción y devuelven true si la acción coincide con cierta condición. Estos matchers pueden usarse en cualquier lugar que necesite verificar si una acción coincide con una condición dada, como dentro de startAppListening. También actúan como guardias de tipo TypeScript, estrechando el tipo TS del objeto action para que puedas acceder a sus campos de forma segura.
Actualmente, el listener de notificaciones observa un único tipo de acción específico con actionCreator: addNewPost.fulfilled. Lo actualizaremos para que observe las publicaciones añadidas con matcher: apiSlice.endpoints.addNewPost.matchFulfilled:
import { createEntityAdapter, createSelector, createSlice, EntityState, PayloadAction } from '@reduxjs/toolkit'
import { client } from '@/api/client'
import type { RootState } from '@/app/store'
import { AppStartListening } from '@/app/listenerMiddleware'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
import { logout } from '@/features/auth/authSlice'
// omit types, posts slice, and selectors
export const addPostsListeners = (startAppListening: AppStartListening) => {
startAppListening({
matcher: apiSlice.endpoints.addNewPost.matchFulfilled,
effect: async (action, listenerApi) => {
Ahora la notificación debería mostrarse correctamente nuevamente cuando añadamos una publicación.
Gestión de datos de usuarios
Hemos terminado de migrar la gestión de datos de publicaciones a RTK Query. A continuación, convertiremos la lista de usuarios.
Como ya hemos visto cómo usar los hooks de RTK Query para obtener y leer datos, en esta sección probaremos un enfoque diferente. Como el resto de Redux Toolkit, la lógica central de RTK Query es agnóstica a la interfaz de usuario y puede usarse con cualquier capa de UI, no solo con React.
Normalmente deberías usar los hooks de React que genera createApi, ya que hacen mucho trabajo por ti. Pero, a modo ilustrativo, aquí trabajaremos con los datos de usuarios usando solo la API central de RTK Query para que veas cómo utilizarla.
Obtención manual de usuarios
Actualmente definimos un thunk asíncrono fetchUsers en usersSlice.ts, y lo despachamos manualmente en main.tsx para que la lista de usuarios esté disponible lo antes posible. Podemos hacer ese mismo proceso usando RTK Query.
Comenzaremos definiendo un endpoint de consulta getUsers en apiSlice.ts, similar a nuestros endpoints existentes. Exportaremos el hook useGetUsersQuery por coherencia, pero por ahora no lo usaremos.
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
import type { Post, NewPost, PostUpdate } from '@/features/posts/postsSlice'
import type { User } from '@/features/users/usersSlice'
export type { Post }
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
getUsers: builder.query<User[], void>({
query: () => '/users'
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useGetUsersQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
Si inspeccionamos el objeto del slice API, incluye un campo endpoints, con un objeto endpoint por cada endpoint que hemos definido.

Cada objeto endpoint contiene:
-
El mismo hook principal de consulta/mutación que exportamos desde el objeto raíz del slice API, pero nombrado como
useQueryouseMutation -
Para endpoints de consulta, un conjunto adicional de hooks para escenarios como "consultas diferidas" o suscripciones parciales
-
Un conjunto de utilidades "matcher" para verificar las acciones
pending/fulfilled/rejecteddespachadas por solicitudes de este endpoint -
Un thunk
initiateque desencadena una solicitud para este endpoint -
Una función
selectque crea selectores memorizados que pueden recuperar los datos en caché y entradas de estado para este endpoint
Si queremos obtener la lista de usuarios fuera de React, podemos despachar el thunk getUsers.initiate() en nuestro archivo principal:
// omit other imports
import { apiSlice } from './features/api/apiSlice'
async function main() {
// Start our mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
store.dispatch(apiSlice.endpoints.getUsers.initiate())
const root = createRoot(document.getElementById('root')!)
root.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>
)
}
main()
Este despacho ocurre automáticamente dentro de los hooks de consulta, pero podemos iniciarlo manualmente si es necesario despachando el thunk initiate.
Ten en cuenta que no proporcionamos un argumento a initiate(). Esto se debe a que nuestro endpoint getUsers no requiere un argumento de consulta específico. Conceptualemente, es lo mismo que decir "esta entrada de caché tiene un argumento de consulta undefined". Si necesitáramos argumentos, los pasaríamos al thunk, como dispatch(apiSlice.endpoints.getPokemon.initiate('pikachu')).
En este caso, estamos despachando manualmente el thunk para comenzar la precarga de datos en la función de configuración de nuestra aplicación. En la práctica, podrías realizar esta precarga en los "data loaders" de React-Router para iniciar las solicitudes antes de renderizar los componentes. (Consulta el hilo de discusión sobre loaders de React-Router en el repositorio de RTK para obtener ideas).
Despachar manualmente un thunk de solicitud RTKQ creará una entrada de suscripción, pero luego depende de ti cancelar esa suscripción posteriormente; de lo contrario, los datos permanecerán en la caché indefinidamente. En este caso, siempre necesitamos datos de usuarios, así que podemos omitir la cancelación de suscripción.
Selección de datos de usuarios
Actualmente tenemos selectores como selectAllUsers y selectUserById que son generados por nuestro adaptador de usuarios createEntityAdapter, y que leen de state.users. Si recargamos la página, toda nuestra visualización relacionada con usuarios se rompe porque el slice state.users no tiene datos. Ahora que estamos obteniendo datos para la caché de RTK Query, deberíamos reemplazar esos selectores por equivalentes que lean de la caché.
La función endpoint.select() en los endpoints del slice de API creará una nueva función selector memoizada cada vez que la llamemos. select() toma una clave de caché como argumento, y esta debe ser la misma clave de caché que pases como argumento a los hooks de consulta o al thunk initiate(). El selector generado usa esa clave de caché para saber exactamente qué resultado en caché debe devolver desde el estado de caché en el store.
En este caso, nuestro endpoint getUsers no necesita parámetros: siempre obtenemos la lista completa de usuarios. Por lo tanto, podemos crear un selector de caché sin argumentos (lo cual es lo mismo que pasar una clave de caché undefined).
Podemos actualizar usersSlice.ts para basar sus selectores en la caché de consultas RTKQ en lugar de en la llamada real a usersSlice:
import {
createEntityAdapter,
createSelector,
createSlice
} from '@reduxjs/toolkit'
import { client } from '@/api/client'
import type { RootState } from '@/app/store'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export interface User {
id: string
name: string
}
// omit `fetchUsers` and `usersSlice`
const emptyUsers: User[] = []
// Calling `someEndpoint.select(someArg)` generates a new selector that will return
// the query result object for a query with those parameters.
// To generate a selector for a specific query argument, call `select(theQueryArg)`.
// In this case, the users query has no params, so we don't pass anything to select()
export const selectUsersResult = apiSlice.endpoints.getUsers.select()
export const selectAllUsers = createSelector(
selectUsersResult,
usersResult => usersResult?.data ?? emptyUsers
)
export const selectUserById = createSelector(
selectAllUsers,
(state: RootState, userId: string) => userId,
(users, userId) => users.find(user => user.id === userId)
)
export const selectCurrentUser = (state: RootState) => {
const currentUsername = selectCurrentUsername(state)
if (currentUsername) {
return selectUserById(state, currentUsername)
}
}
/* Temporarily ignore adapter selectors - we'll come back to this later
export const { selectAll: selectAllUsers, selectById: selectUserById } = usersAdapter.getSelectors(
(state: RootState) => state.users,
)
*/
Comenzamos creando una instancia de selector específica selectUsersResult que sepa cómo recuperar la entrada de caché correcta.
Una vez que tenemos ese selector inicial selectUsersResult, podemos reemplazar el selector existente selectAllUsers con uno que devuelva el array de usuarios desde el resultado de la caché. Como podría no haber un resultado válido todavía, recurrimos a un array emptyUsers. También reemplazaremos selectUserById con uno que encuentre el usuario correcto en ese array.
Por ahora vamos a comentar esos selectores del usersAdapter: más adelante haremos otro cambio que volverá a utilizarlos.
Nuestros componentes ya están importando selectAllUsers, selectUserById y selectCurrentUser, ¡así que este cambio debería funcionar directamente! Prueba a recargar la página y navegar por la lista de publicaciones y la vista individual de una publicación. Los nombres de usuario correctos deberían aparecer en cada publicación mostrada y en el desplegable de <AddPostForm>.
¡Nota que este es un gran ejemplo de cómo el uso de selectores hace el código más mantenible! Nuestros componentes ya llamaban a estos selectores, así que no les importa si los datos provienen del estado existente en usersSlice o de una entrada de caché de RTK Query, siempre que los selectores devuelvan los datos esperados. Pudimos cambiar las implementaciones de los selectores y no tuvimos que actualizar los componentes de UI en absoluto.
Como el estado de usersSlice ya ni siquiera se utiliza, podemos proceder a eliminar la llamada const usersSlice = createSlice() y el thunk fetchUsers de este archivo, además de quitar users: usersReducer de la configuración del store. Todavía tenemos algunos fragmentos de código que hacen referencia a postsSlice, así que no podemos eliminarlo aún; lo abordaremos más adelante.
División e inyección de endpoints
Dijimos que RTK Query normalmente tiene un único "API slice" por aplicación, y hasta ahora hemos definido todos nuestros puntos finales directamente en apiSlice.ts. Pero es común que aplicaciones más grandes dividan características mediante "code-splitting" en paquetes separados y luego las carguen bajo demanda ("lazy load") cuando la característica se usa por primera vez. ¿Qué sucede si queremos aplicar code-splitting a algunas definiciones de puntos finales, o moverlas a otro archivo para evitar que el archivo del segmento de API crezca demasiado?
RTK Query permite dividir definiciones de endpoints mediante apiSlice.injectEndpoints(). Así podemos mantener una única instancia de API slice, con un único middleware y reducer de caché, pero mover la definición de algunos endpoints a otros archivos. Esto habilita escenarios de división de código y permite colocar endpoints junto a carpetas de funcionalidades si se desea.
Para ilustrar este proceso, migremos el endpoint getUsers para inyectarlo en usersSlice.ts en lugar de definirlo en apiSlice.ts.
Ya importamos apiSlice en usersSlice.ts para acceder al endpoint getUsers, así que podemos cambiar a llamar apiSlice.injectEndpoints() aquí.
import { apiSlice } from '../api/apiSlice'
// This is the _same_ reference as `apiSlice`, but this has
// the TS types updated to include the injected endpoints
export const apiSliceWithUsers = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query<User[], void>({
query: () => '/users'
})
})
})
export const { useGetUsersQuery } = apiSliceWithUsers
export const selectUsersResult = apiSliceWithUsers.endpoints.getUsers.select()
injectEndpoints() mutates el objeto API slice original para añadir definiciones de endpoints adicionales y devuelve la misma referencia de API. Además, el valor retornado por injectEndpoints incluye tipos TS adicionales de los endpoints inyectados.
Por ello, debemos guardar esto en una nueva variable con nombre diferente para usar los tipos TS actualizados, asegurar la compilación correcta y recordar qué versión del API slice estamos usando. Aquí lo llamaremos apiSliceWithUsers para diferenciarlo del apiSlice original.
Actualmente, el único archivo que referencia el endpoint getUsers es nuestro punto de entrada, que despacha el thunk initiate. Debemos actualizarlo para importar el API slice extendido:
import { apiSliceWithUsers } from './features/users/usersSlice'
import { worker } from './api/server'
import './index.css'
// Wrap app rendering so we can wait for the mock API to initialize
async function start() {
// Start our mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
store.dispatch(apiSliceWithUsers.endpoints.getUsers.initiate())
const root = createRoot(document.getElementById('root')!)
root.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>
)
}
Alternativamente, podrías exportar los endpoints específicos directamente desde el archivo del slice, como hacíamos con los action creators en los slices.
Manipulación de datos de respuesta
Hasta ahora, todos nuestros endpoints de query han almacenado los datos de respuesta del servidor exactamente como se recibieron en el cuerpo. getPosts y getUsers esperan que el servidor devuelva un array, y getPost espera el objeto Post individual como cuerpo.
Es común que los clientes necesiten extraer fragmentos de datos de la respuesta del servidor o transformarlos antes de almacenarlos en caché. Por ejemplo, ¿y si la petición /getPost devuelve un cuerpo como {post: {id}}, con los datos anidados?
Conceptualmente, hay varias formas de abordarlo. Una opción sería extraer el campo responseData.post y almacenarlo en la caché en lugar del cuerpo completo. Otra sería almacenar todos los datos de respuesta en caché, pero hacer que nuestros componentes especifiquen solo una parte concreta de esos datos almacenados.
Transformación de respuestas
Los endpoints pueden definir un manejador transformResponse que extraiga o modifique los datos del servidor antes de almacenarlos en caché. Por ejemplo, si getPost devolviera {post: {id}}, podríamos usar transformResponse: (responseData) => responseData.post, y almacenaría solo el objeto Post real en lugar de todo el cuerpo de la respuesta.
En la Parte 6: Rendimiento y Normalización, analizamos por qué es útil almacenar datos en una estructura normalizada. En particular, nos permite buscar y actualizar elementos por ID, en lugar de tener que recorrer un array para encontrar el elemento correcto.
Nuestro selector selectUserById actualmente debe recorrer el array en caché de usuarios para encontrar el objeto User correcto. Si transformáramos los datos de respuesta para almacenarlos de forma normalizada, podríamos simplificar esto buscando directamente el usuario por ID.
Anteriormente usábamos createEntityAdapter en usersSlice para gestionar datos de usuarios normalizados. Podemos integrar createEntityAdapter en nuestro extendedApiSlice, y usar createEntityAdapter para transformar los datos antes de almacenarlos en caché. Reactivaremos las líneas de usersAdapter que teníamos originalmente y volveremos a usar sus funciones de actualización y selectores.
import {
createSelector,
createEntityAdapter,
EntityState
} from '@reduxjs/toolkit'
import type { RootState } from '@/app/store'
import { apiSlice } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export interface User {
id: string
name: string
}
const usersAdapter = createEntityAdapter<User>()
const initialState = usersAdapter.getInitialState()
// This is the _same_ reference as `apiSlice`, but this has
// the TS types updated to include the injected endpoints
export const apiSliceWithUsers = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query<EntityState<User, string>, void>({
query: () => '/users',
transformResponse(res: User[]) {
// Create a normalized state object containing all the user items
return usersAdapter.setAll(initialState, res)
}
})
})
})
export const { useGetUsersQuery } = apiSliceWithUsers
// Calling `someEndpoint.select(someArg)` generates a new selector that will return
// the query result object for a query with those parameters.
// To generate a selector for a specific query argument, call `select(theQueryArg)`.
// In this case, the users query has no params, so we don't pass anything to select()
export const selectUsersResult = apiSliceWithUsers.endpoints.getUsers.select()
const selectUsersData = createSelector(
selectUsersResult,
// Fall back to the empty entity state if no response yet.
result => result.data ?? initialState
)
export const selectCurrentUser = (state: RootState) => {
const currentUsername = selectCurrentUsername(state)
if (currentUsername) {
return selectUserById(state, currentUsername)
}
}
export const { selectAll: selectAllUsers, selectById: selectUserById } =
usersAdapter.getSelectors(selectUsersData)
Hemos añadido una opción transformResponse al endpoint getUsers. Recibe todo el cuerpo de datos de respuesta como argumento (en este caso, un array User[]), y debe devolver los datos reales para almacenar en caché. Al llamar a usersAdapter.setAll(initialState, responseData), devolverá la estructura de datos normalizada estándar {ids: [], entities: {}} que contiene todos los elementos recibidos. Debemos indicar a TypeScript que ahora devolvemos esos datos EntityState<User, string> como contenido real del campo data de la entrada de caché.
La función adapter.getSelectors() necesita un "selector de entrada" para saber dónde encontrar esos datos normalizados. En este caso, los datos están anidados dentro del reducer de caché de RTK Query, así que seleccionamos el campo adecuado del estado de caché. Para mayor coherencia, podemos escribir un selector selectUsersData que recurra al estado normalizado vacío inicial si aún no hemos obtenido los datos.
Cachés normalizadas frente a cachés de documentos
Vale la pena detenerse un momento para analizar lo que acabamos de hacer y por qué es importante.
Puede que hayas oído el término "caché normalizada" en relación con otras bibliotecas de obtención de datos como Apollo. Es importante entender que RTK Query utiliza un enfoque de "caché de documentos", no una "caché normalizada".
Una caché completamente normalizada intenta desduplicar elementos similares en todas las consultas, basándose en tipo e ID de elemento. Por ejemplo, supongamos que tenemos un slice de API con endpoints getTodos y getTodo, y nuestros componentes realizan estas consultas:
-
getTodos() -
getTodos({filter: 'odd'}) -
getTodo({id: 1})
Cada uno de estos resultados de consulta incluiría un objeto Todo similar a {id: 1}.
En una caché completamente normalizada con desduplicación, solo se almacenaría una copia de este objeto Todo. Sin embargo, RTK Query guarda cada resultado de consulta de forma independiente en la caché. Esto resultaría en tres copias separadas de este Todo almacenadas en la caché de Redux. No obstante, si todos los endpoints proporcionan consistentemente las mismas etiquetas (como {type: 'Todo', id: 1}), invalidar esa etiqueta forzará a todos los endpoints coincidentes a volver a obtener sus datos para mantener la coherencia.
RTK Query no implementa deliberadamente una caché que desduplique elementos idénticos en múltiples solicitudes. Hay varias razones para esto:
-
Una caché completamente normalizada compartida entre consultas es un problema difícil de resolver
-
No tenemos tiempo, recursos ni interés en resolver eso ahora mismo
-
En muchos casos, simplemente volver a obtener datos cuando se invalidan funciona bien y es más fácil de entender
-
El objetivo principal de RTKQ es ayudar a resolver el caso de uso general de "obtener algunos datos", que es un gran punto de dolor para mucha gente
En este caso, simplemente normalizamos los datos de respuesta para el endpoint getUsers, almacenándolos como una tabla de búsqueda {[id]: value}. Sin embargo, esto no es lo mismo que una "caché normalizada" - solo transformamos cómo se almacena esta respuesta específica, en lugar de desduplicar resultados entre endpoints o solicitudes.
Selección de valores a partir de resultados
El último componente que lee del antiguo postsSlice es <UserPage>, que filtra la lista de publicaciones según el usuario actual. Ya hemos visto que podemos obtener toda la lista de publicaciones con useGetPostsQuery() y luego transformarla en el componente, como ordenar dentro de un useMemo. Los hooks de consulta también nos permiten seleccionar partes del estado en caché mediante la opción selectFromResult, y solo vuelven a renderizar el componente cuando cambian las partes seleccionadas.
Los hooks useQuery siempre reciben el argumento de clave de caché como primer parámetro. Si necesitas pasar opciones al hook, deben ir siempre como segundo parámetro: useSomeQuery(cacheKey, options). En este caso, el endpoint getUsers no tiene ningún argumento de clave de caché real. Semánticamente, esto equivale a una clave de caché undefined. Por lo tanto, para pasar opciones al hook, debemos llamarlo como useGetUsersQuery(undefined, options).
Podemos usar selectFromResult para que <UserPage> lea solo una lista filtrada de publicaciones desde la caché. Sin embargo, para que selectFromResult evite renderizados innecesarios, debemos garantizar que los datos extraídos estén correctamente memorizados. Para ello, debemos crear una nueva instancia de selector que el componente <UserPage> pueda reutilizar en cada renderizado, asegurando que el selector memorice el resultado según sus entradas.
import { Link, useParams } from 'react-router-dom'
import { createSelector } from '@reduxjs/toolkit'
import type { TypedUseQueryStateResult } from '@reduxjs/toolkit/query/react'
import { useAppSelector } from '@/app/hooks'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
import { selectUserById } from './usersSlice'
// Create a TS type that represents "the result value passed
// into the `selectFromResult` function for this hook"
type GetPostsSelectFromResultArg = TypedUseQueryStateResult<Post[], any, any>
const selectPostsForUser = createSelector(
(res: GetPostsSelectFromResultArg) => res.data,
(res: GetPostsSelectFromResultArg, userId: string) => userId,
(data, userId) => data?.filter(post => post.user === userId)
)
export const UserPage = () => {
const { userId } = useParams()
const user = useAppSelector(state => selectUserById(state, userId!))
// Use the same posts query, but extract only part of its data
const { postsForUser } = useGetPostsQuery(undefined, {
selectFromResult: result => ({
// Optional: Include all of the existing result fields like `isFetching`
...result,
// Include a field called `postsForUser` in the result object,
// which will be a filtered list of posts
postsForUser: selectPostsForUser(result, userId!)
})
})
// omit rendering logic
}
Existe una diferencia clave con la función de selector memorizado que hemos creado. Normalmente, los selectores esperan todo el state de Redux como primer argumento, extrayendo o derivando un valor del state. Sin embargo, aquí solo trabajamos con el valor "resultado" almacenado en la caché. Este objeto resultado tiene un campo data con los valores reales que necesitamos, además de metadatos de la solicitud.
Como este selector recibe algo distinto al típico tipo RootState como primer argumento, debemos indicar a TypeScript cómo es ese valor resultado. El paquete RTK Query exporta un tipo TypeScript llamado TypedUseQueryStateResult que representa "el tipo del objeto devuelto por el hook useQuery". Podemos usarlo para declarar que esperamos que el resultado incluya un array Post[], y luego definir nuestro selector usando ese tipo.
En RTK 2.x y Reselect 5.x, los selectores memorizados tienen un tamaño de caché infinito, por lo que cambiar los argumentos mantendrá disponibles los resultados memorizados anteriores. Si usas RTK 1.x o Reselect 4.x, ten en cuenta que los selectores memorizados tienen un tamaño de caché predeterminado de 1. Deberás crear una instancia de selector única por componente para garantizar que el selector memorice consistentemente al recibir argumentos diferentes como IDs.
Nuestro callback selectFromResult recibe el objeto result que contiene los metadatos de la solicitud original y los data del servidor, y debe devolver valores extraídos o derivados. Como los hooks de consulta agregan un método refetch adicional a lo que se devuelve aquí, selectFromResult siempre debe devolver un objeto con los campos internos que necesites.
Como result se mantiene en el store de Redux, no podemos mutarlo - debemos devolver un nuevo objeto. El hook de consulta realizará una comparación "superficial" de este objeto devuelto, y solo volverá a renderizar el componente si alguno de los campos ha cambiado. Podemos optimizar los re-renderizados devolviendo únicamente los campos específicos que necesita este componente - si no necesitas el resto de metadatos, puedes omitirlos por completo. Si sí los necesitas, puedes expandir el valor original de result para incluirlos en la salida.
En este caso, llamaremos al campo postsForUser, y podemos desestructurar ese nuevo campo del resultado del hook. Al llamar a selectPostsForUser(result, userId) cada vez, memorizará el array filtrado y solo lo recalculará si los datos obtenidos o el ID de usuario cambian.
Comparación de enfoques de transformación
Hemos visto tres formas diferentes de gestionar la transformación de respuestas:
-
Mantener la respuesta original en caché, leer el resultado completo en el componente y derivar valores
-
Mantener la respuesta original en caché, leer el resultado derivado con
selectFromResult -
Transformar la respuesta antes de almacenarla en caché
Cada uno de estos enfoques puede ser útil en diferentes situaciones. Aquí tienes algunas sugerencias sobre cuándo considerarlos:
-
transformResponse: cuando todos los consumidores del endpoint quieren un formato específico, como normalizar la respuesta para permitir búsquedas más rápidas por ID -
selectFromResult: cuando algunos consumidores del endpoint solo necesitan datos parciales, como una lista filtrada -
Por componente /
useMemo: cuando solo algunos componentes específicos necesitan transformar los datos en caché
Actualizaciones avanzadas de caché
Hemos completado la actualización de datos de publicaciones y usuarios, así que solo nos queda trabajar con reacciones y notificaciones. Migrar estos a RTK Query nos permitirá probar técnicas avanzadas para trabajar con datos en caché y ofrecer una mejor experiencia de usuario.
Persistencia de reacciones
Originalmente, solo rastreábamos las reacciones en el cliente sin persistirlas en el servidor. Añadamos una nueva mutación addReaction para actualizar el Post correspondiente en el servidor cada vez que el usuario haga clic en un botón de reacción.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
addReaction: builder.mutation<
Post,
{ postId: string; reaction: ReactionName }
>({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// In a real app, we'd probably need to base this on user ID somehow
// so that a user can't do the same reaction more than once
body: { reaction }
}),
invalidatesTags: (result, error, arg) => [
{ type: 'Post', id: arg.postId }
]
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation,
useAddReactionMutation
} = apiSlice
Como en otras mutaciones, tomamos parámetros y hacemos una petición al servidor con datos en el cuerpo. Dado que esta aplicación es pequeña, enviaremos solo el nombre de la reacción y dejaremos que el servidor incremente el contador para ese tipo de reacción en la publicación.
Ya sabemos que necesitamos reobtener esta publicación para ver los cambios en el cliente, así que podemos invalidar esta entrada específica de Post por su ID.
Con esto listo, actualicemos <ReactionButtons> para usar esta mutación.
import { useAddReactionMutation } from '@/features/api/apiSlice'
import type { Post, ReactionName } from './postsSlice'
const reactionEmoji: Record<ReactionName, string> = {
thumbsUp: '👍',
tada: '🎉',
heart: '❤️',
rocket: '🚀',
eyes: '👀'
}
interface ReactionButtonsProps {
post: Post
}
export const ReactionButtons = ({ post }: ReactionButtonsProps) => {
const [addReaction] = useAddReactionMutation()
const reactionButtons = Object.entries(reactionEmoji).map(
([stringName, emoji]) => {
// Ensure TS knows this is a _specific_ string type
const reaction = stringName as ReactionName
return (
<button
key={reaction}
type="button"
className="muted-button reaction-button"
onClick={() => {
addReaction({ postId: post.id, reaction })
}}
>
{emoji} {post.reactions[reaction]}
</button>
)
}
)
return <div>{reactionButtons}</div>
}
¡Veámoslo en acción! Ve a la lista principal <PostsList> y haz clic en una reacción para ver qué sucede.
Vaya. Todo el componente <PostsList> se atenuó porque reobtuvimos la lista completa de publicaciones al actualizar una sola. Esto es deliberadamente visible porque nuestro servidor de simulación tiene un retraso de 2 segundos, pero incluso con respuestas más rápidas, no es una buena experiencia de usuario.
Actualizaciones optimistas para reacciones
Para una actualización pequeña como añadir una reacción, probablemente no necesitemos reobtener toda la lista. En su lugar, podríamos actualizar directamente los datos en caché del cliente para reflejar lo que esperamos que suceda en el servidor. Además, si actualizamos la caché inmediatamente, el usuario recibe retroalimentación instantánea al hacer clic en lugar de esperar la respuesta. Este enfoque de actualizar el estado del cliente inmediatamente se llama "actualización optimista" y es un patrón común en aplicaciones web.
RTK Query incluye utilidades para actualizar directamente la caché del cliente. Esto se puede combinar con los métodos de "ciclo de vida de solicitud" de RTK Query para implementar actualizaciones optimistas.
Utilidades de actualización de caché
Las API slices incluyen métodos adicionales bajo api.util. Esto incluye thunks para modificar la caché: upsertQueryData para añadir o reemplazar una entrada, y updateQueryData para modificar una entrada. Al ser thunks, pueden usarse en cualquier lugar donde tengas acceso a dispatch.
En particular, el thunk util updateQueryData toma tres argumentos: el nombre del endpoint a actualizar, el mismo argumento de clave de caché usado para identificar la entrada específica, y un callback que modifica los datos cacheados. updateQueryData utiliza Immer, por lo que puedes "mutar" los datos cacheados en borrador igual que harías en createSlice:
dispatch(
apiSlice.util.updateQueryData(endpointName, queryArg, draft => {
// mutate `draft` here like you would in a reducer
draft.value = 123
})
)
updateQueryData genera un objeto de acción con un diff de los cambios. Al despachar esa acción, el valor devuelto de dispatch es un objeto patchResult. Si llamamos a patchResult.undo(), se despacha automáticamente una acción que revierte los cambios del diff.
El ciclo de vida onQueryStarted
El primer método del ciclo de vida que veremos es onQueryStarted. Esta opción está disponible tanto para queries como para mutations.
Si se proporciona, onQueryStarted se llamará cada vez que se realice una nueva petición. Esto nos da un lugar para ejecutar lógica adicional en respuesta a la solicitud.
Similar a los thunks asíncronos y los efectos de listener, el callback onQueryStarted recibe el valor del argumento arg de la query como primer argumento, y un objeto lifecycleApi como segundo. lifecycleApi incluye los mismos valores {dispatch, getState, extra, requestId} que createAsyncThunk. También tiene campos adicionales únicos de este ciclo. El más importante es lifecycleApi.queryFulfilled, una Promise que se resolverá cuando la petición finalice, cumpliéndose o rechazándose según el resultado.
Implementar actualizaciones optimistas
Podemos usar las utilidades de actualización dentro del ciclo de vida onQueryStarted para implementar actualizaciones "optimistas" (actualizando la caché antes de que finalice la petición) o actualizaciones "pesimistas" (actualizando la caché después de que finalice).
Podemos implementar la actualización optimista encontrando la entrada Post específica en la caché de getPosts, y "mutándola" para incrementar el contador de reacciones. También podríamos tener una segunda copia del mismo objeto Post individual en la caché getPost para ese ID, por lo que necesitamos actualizar esa entrada si existe.
Por defecto, asumimos que la petición tendrá éxito. Si falla, podemos await lifecycleApi.queryFulfilled, capturar el fallo y deshacer los cambios para revertir la actualización optimista.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
addReaction: builder.mutation<
Post,
{ postId: string; reaction: ReactionName }
>({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// In a real app, we'd probably need to base this on user ID somehow
// so that a user can't do the same reaction more than once
body: { reaction }
}),
// The `invalidatesTags` line has been removed,
// since we're now doing optimistic updates
async onQueryStarted({ postId, reaction }, lifecycleApi) {
// `updateQueryData` requires the endpoint name and cache key arguments,
// so it knows which piece of cache state to update
const getPostsPatchResult = lifecycleApi.dispatch(
apiSlice.util.updateQueryData('getPosts', undefined, draft => {
// The `draft` is Immer-wrapped and can be "mutated" like in createSlice
const post = draft.find(post => post.id === postId)
if (post) {
post.reactions[reaction]++
}
})
)
// We also have another copy of the same data in the `getPost` cache
// entry for this post ID, so we need to update that as well
const getPostPatchResult = lifecycleApi.dispatch(
apiSlice.util.updateQueryData('getPost', postId, draft => {
draft.reactions[reaction]++
})
)
try {
await lifecycleApi.queryFulfilled
} catch {
getPostsPatchResult.undo()
getPostPatchResult.undo()
}
}
})
})
})
En este caso, también hemos eliminado la línea invalidatesTags que acabábamos de añadir, ya que no queremos recargar las publicaciones al hacer clic en un botón de reacción.
Ahora, si hacemos clic varias veces rápidamente en un botón de reacción, veremos que el número se incrementa en la interfaz cada vez. Si miramos la pestaña Network, también veremos cada petición individual enviarse al servidor.
A veces las mutaciones devuelven datos significativos en la respuesta del servidor, como un ID final que debe reemplazar un ID temporal del cliente. Si primero hacemos const res = await lifecycleApi.queryFulfilled, podríamos usar los datos de la respuesta para aplicar actualizaciones a la caché como una actualización "pesimista".
Actualizaciones en streaming para notificaciones
Nuestra última característica es la pestaña de notificaciones. Cuando construimos originalmente esta funcionalidad en Parte 6, mencionamos que "en una aplicación real, el servidor enviaría actualizaciones a nuestro cliente cada vez que ocurre algo". Inicialmente simulamos esta funcionalidad añadiendo un botón "Actualizar notificaciones" que realiza una petición HTTP GET para obtener más entradas de notificaciones.
Es común que las aplicaciones realicen una petición inicial para obtener datos del servidor y luego abran una conexión Websocket para recibir actualizaciones adicionales con el tiempo. Los métodos del ciclo de vida de RTK Query nos permiten implementar ese tipo de "actualizaciones en streaming" para datos en caché.
Ya hemos visto el ciclo de vida onQueryStarted que nos permite implementar actualizaciones optimistas (o pesimistas). Además, RTK Query proporciona un manejador del ciclo de vida onCacheEntryAdded para endpoints, que es un lugar ideal para implementar actualizaciones en streaming. Usaremos esta capacidad para implementar un enfoque más realista de gestión de notificaciones.
El ciclo de vida onCacheEntryAdded
Al igual que onQueryStarted, el método del ciclo de vida onCacheEntryAdded está disponible tanto para consultas como para mutaciones.
onCacheEntryAdded se invoca cada vez que se añade una nueva entrada a la caché (endpoint + argumento de consulta serializado). Esto significa que se ejecuta con menos frecuencia que onQueryStarted, que se activa en cada petición.
Similar a onQueryStarted, onCacheEntryAdded recibe dos parámetros. El primero es el valor habitual de args de la consulta. El segundo es un lifecycleApi ligeramente diferente que contiene {dispatch, getState, extra, requestId}, además de una utilidad updateCachedData, una forma alternativa de api.util.updateQueryData que ya conoce el nombre del endpoint y los argumentos de consulta a usar y realiza el despacho por ti.
También hay dos Promesas adicionales que se pueden esperar:
-
cacheDataLoaded: se resuelve con el primer valor almacenado en caché, y se usa típicamente para esperar un valor real en caché antes de ejecutar más lógica -
cacheEntryRemoved: se resuelve cuando esta entrada de la caché se elimina (es decir, no hay más suscriptores y la entrada de la caché ha sido recolectada como basura)
Mientras haya al menos un suscriptor activo para los datos, la entrada en caché permanece activa. Cuando el número de suscriptores llega a cero y expira el temporizador de vida útil de la caché, la entrada se elimina y cacheEntryRemoved se resuelve. El patrón de uso típico es:
-
await cacheDataLoadedinmediatamente -
Crear una suscripción de datos del servidor (como un Websocket)
-
Al recibir una actualización, usar
updateCachedDatapara "mutar" los valores en caché basándose en la actualización -
await cacheEntryRemovedal final -
Limpiar las suscripciones posteriormente
Esto convierte onCacheEntryAdded en un lugar ideal para lógica de larga duración que debe continuar mientras la interfaz necesite estos datos específicos. Un buen ejemplo sería una aplicación de chat que obtiene mensajes iniciales para un canal, usa una suscripción Websocket para recibir mensajes adicionales y desconecta el Websocket cuando el usuario cierra el canal.
Obtención de notificaciones
Necesitamos dividir este trabajo en varios pasos.
Primero, configuraremos un nuevo endpoint para notificaciones y añadiremos un reemplazo para el thunk fetchNotificationsWebsocket que activará nuestro backend simulado para enviar notificaciones mediante websocket en lugar de peticiones HTTP.
Inyectaremos el endpoint getNotifications en notificationsSlice como hicimos con getUsers, simplemente para mostrar que es posible.
import { createEntityAdapter, createSlice } from '@reduxjs/toolkit'
import { client } from '@/api/client'
import { forceGenerateNotifications } from '@/api/server'
import type { AppThunk, RootState } from '@/app/store'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
// omit types and `fetchNotifications` thunk
export const apiSliceWithNotifications = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query<ServerNotification[], void>({
query: () => '/notifications'
})
})
})
export const { useGetNotificationsQuery } = apiSliceWithNotifications
getNotifications es un endpoint de consulta estándar que almacenará los objetos ServerNotification que recibamos del servidor.
Luego, en <Navbar>, podemos usar el nuevo hook de consulta para obtener automáticamente algunas notificaciones. Al hacer esto, solo recibimos objetos ServerNotification, no los objetos ClientNotification con los campos adicionales {read, isNew} que hemos estado añadiendo. Por lo tanto, tendremos que desactivar temporalmente la comprobación de notification.new:
// omit other imports
import { allNotificationsRead, useGetNotificationsQuery } from './notificationsSlice'
export const NotificationsList = () => {
const dispatch = useAppDispatch()
const { data: notifications = [] } = useGetNotificationsQuery()
useLayoutEffect(() => {
dispatch(allNotificationsRead())
})
const renderedNotifications = notifications.map((notification) => {
const notificationClassname = classnames('notification', {
// new: notification.isNew,
})
}
// omit rendering
}
Si accedemos a la pestaña "Notificaciones", deberíamos ver algunas entradas, pero ninguna estará coloreada para indicar que son nuevas. Mientras tanto, si hacemos clic en el botón "Actualizar notificaciones", veremos que el contador de "notificaciones no leídas" sigue aumentando. Esto se debe a dos razones: el botón todavía activa el thunk original fetchNotifications que almacena entradas en el slice state.notifications. Además, el componente <NotificationsList> ni siquiera se vuelve a renderizar (depende de los datos en caché del hook useGetNotificationsQuery, no del slice state.notifications), por lo que useLayoutEffect no se ejecuta ni despacha allNotificationsRead.
Seguimiento del estado en el cliente
El siguiente paso es reconsiderar cómo rastreamos el estado de "leído" para las notificaciones.
Anteriormente, tomábamos los objetos ServerNotification obtenidos del thunk fetchNotifications, añadíamos los campos {read, isNew} en el reducer y guardábamos esos objetos. Ahora, estamos guardando los objetos ServerNotification en la caché de RTK Query.
Podríamos hacer más actualizaciones manuales de la caché. Podríamos usar transformResponse para añadir los campos adicionales y luego trabajar para modificar la propia caché a medida que el usuario ve las notificaciones.
En su lugar, vamos a probar una variante de lo que ya hacíamos: mantener el seguimiento del estado de leído dentro del slice notificationsSlice.
Conceptualmente, lo que realmente queremos es rastrear el estado {read, isNew} de cada notificación. Podríamos hacerlo en el slice manteniendo una entrada de "metadatos" correspondiente para cada notificación recibida, si tuviéramos forma de saber cuándo el hook de consulta ha obtenido notificaciones y acceder a sus IDs.
¡Afortunadamente podemos hacerlo! Como RTK Query está construido con piezas estándar de Redux Toolkit como createAsyncThunk, despacha una acción fulfilled con los resultados cada vez que una solicitud finaliza. Solo necesitamos una forma de escuchar esto en notificationsSlice, y sabemos que createSlice.extraReducers es donde debemos manejar esa acción.
¿Pero qué estamos escuchando? Como es un endpoint de RTKQ, no tenemos acceso a los creadores de acciones asyncThunk.fulfilled/pending, por lo que no podemos simplemente pasarlos a builder.addCase().
Los endpoints de RTK Query exponen una función matcher matchFulfilled, que podemos usar dentro de extraReducers para escuchar las acciones fulfilled de ese endpoint (nota: debemos cambiar de builder.addCase() a builder.addMatcher()).
Así que cambiaremos ClientNotification a un nuevo tipo NotificationMetadata, escucharemos las acciones de consulta getNotifications y almacenaremos los objetos de "solo metadatos" en el slice en lugar de las notificaciones completas.
Como parte de esto, renombraremos notificationsAdapter a metadataAdapter y reemplazaremos todas las menciones de variables notification por metadata para mayor claridad. Parecen muchos cambios, pero es principalmente renombrar variables.
También exportaremos el selector selectEntities del adaptador de entidades como selectMetadataEntities. Necesitaremos buscar estos objetos de metadatos por ID en la UI, y será más fácil si tenemos la tabla de búsqueda disponible en el componente.
// omit imports and thunks
// Replaces `ClientNotification`, since we just need these fields
export interface NotificationMetadata {
// Add an `id` field, since this is now a standalone object
id: string
read: boolean
isNew: boolean
}
export const fetchNotifications = createAppAsyncThunk(
'notifications/fetchNotifications',
async (_unused, thunkApi) => {
// Deleted timestamp lookups - we're about to remove this thunk anyway
const response = await client.get<ServerNotification[]>(
`/fakeApi/notifications`
)
return response.data
}
)
// Renamed from `notificationsAdapter`, and we don't need sorting
const metadataAdapter = createEntityAdapter<NotificationMetadata>()
const initialState = metadataAdapter.getInitialState()
const notificationsSlice = createSlice({
name: 'notifications',
initialState,
reducers: {
allNotificationsRead(state) {
// Rename to `metadata`
Object.values(state.entities).forEach(metadata => {
metadata.read = true
})
}
},
extraReducers(builder) {
// Listen for the endpoint `matchFulfilled` action with `addMatcher`
builder.addMatcher(
apiSliceWithNotifications.endpoints.getNotifications.matchFulfilled,
(state, action) => {
// Add client-side metadata for tracking new notifications
const notificationsMetadata: NotificationMetadata[] =
action.payload.map(notification => ({
// Give the metadata object the same ID as the notification
id: notification.id,
read: false,
isNew: true
}))
// Rename to `metadata`
Object.values(state.entities).forEach(metadata => {
// Any notifications we've read are no longer new
metadata.isNew = !metadata.read
})
metadataAdapter.upsertMany(state, notificationsMetadata)
}
)
}
})
export const { allNotificationsRead } = notificationsSlice.actions
export default notificationsSlice.reducer
// Rename the selector
export const {
selectAll: selectAllNotificationsMetadata,
selectEntities: selectMetadataEntities
} = metadataAdapter.getSelectors(
(state: RootState) => state.notifications
)
export const selectUnreadNotificationsCount = (state: RootState) => {
const allMetadata = selectAllNotificationsMetadata(state)
const unreadNotifications = allMetadata.filter(metadata => !metadata.read)
return unreadNotifications.length
}
Luego podemos leer esa tabla de búsqueda de metadatos en <NotificationsList>, buscar el objeto de metadatos correcto para cada notificación que renderizamos y reactivar la comprobación de isNew para mostrar el estilo correcto:
import { allNotificationsRead, useGetNotificationsQuery, selectMetadataEntities } from './notificationsSlice'
export const NotificationsList = () => {
const dispatch = useAppDispatch()
const { data: notifications = [] } = useGetNotificationsQuery()
const notificationsMetadata = useAppSelector(selectMetadataEntities)
useLayoutEffect(() => {
dispatch(allNotificationsRead())
})
const renderedNotifications = notifications.map((notification) => {
// Get the metadata object matching this notification
const metadata = notificationsMetadata[notification.id]
const notificationClassname = classnames('notification', {
// re-enable the `isNew` check for styling
new: metadata.isNew,
})
// omit rendering
}
}
Ahora, si miramos la pestaña "Notificaciones", las nuevas notificaciones tienen el estilo correcto... pero todavía no obtenemos más notificaciones, ni estas se marcan como leídas.
Notificaciones Push mediante Websocket
Nos quedan un par de pasos para completar la transición a recibir más notificaciones mediante push del servidor.
El siguiente paso es cambiar el botón "Refresh Notifications" para que, en lugar de despachar un thunk asíncrono que obtiene datos mediante HTTP, fuerce al backend simulado a enviar notificaciones a través de un websocket.
Nuestro archivo src/api/server.ts ya tiene configurado un servidor Websocket simulado, similar al servidor HTTP simulado. Como no tenemos un backend real (¡ni otros usuarios!), aún necesitamos indicar manualmente al servidor simulado cuándo enviar nuevas notificaciones, así que seguiremos simulando esto con un botón que al hacer clic fuerza la actualización. Para ello, server.ts exporta una función llamada forceGenerateNotifications, que forzará al backend a enviar algunas notificaciones a través de ese websocket.
Vamos a reemplazar el thunk asíncrono fetchNotifications por un thunk fetchNotificationsWebsocket. fetchNotificationsWebsocket realiza un trabajo similar al thunk asíncrono fetchNotifications existente. Sin embargo, en este caso no estamos haciendo una petición HTTP real, así que no hay llamada await ni payload que devolver. Simplemente llamamos a una función que server.ts exportó específicamente para permitirnos simular notificaciones push del servidor.
Por ello, fetchNotificationsWebsocket ni siquiera necesita usar createAsyncThunk. Es simplemente un thunk normal escrito manualmente, así que podemos usar el tipo AppThunk para describir el tipo de la función thunk y tener tipos correctos para (dispatch, getState).
Para implementar la comprobación de "último timestamp", necesitamos añadir selectores que nos permitan leer también de la entrada de caché de notificaciones. Usaremos el mismo patrón que vimos con el slice de usuarios.
import {
createEntityAdapter,
createSlice,
createSelector
} from '@reduxjs/toolkit'
import { forceGenerateNotifications } from '@/api/server'
import type { AppThunk, RootState } from '@/app/store'
import { apiSlice } from '@/features/api/apiSlice'
// omit types and API slice setup
export const { useGetNotificationsQuery } = apiSliceWithNotifications
export const fetchNotificationsWebsocket =
(): AppThunk => (dispatch, getState) => {
const allNotifications = selectNotificationsData(getState())
const [latestNotification] = allNotifications
const latestTimestamp = latestNotification?.date ?? ''
// Hardcode a call to the mock server to simulate a server push scenario over websockets
forceGenerateNotifications(latestTimestamp)
}
const emptyNotifications: ServerNotification[] = []
export const selectNotificationsResult =
apiSliceWithNotifications.endpoints.getNotifications.select()
const selectNotificationsData = createSelector(
selectNotificationsResult,
notificationsResult => notificationsResult.data ?? emptyNotifications
)
// omit slice and selectors
Luego podemos modificar <Navbar> para que despache fetchNotificationsWebsocket en su lugar:
import {
fetchNotificationsWebsocket,
selectUnreadNotificationsCount,
} from '@/features/notifications/notificationsSlice'
import { selectCurrentUser } from '@/features/users/usersSlice'
import { UserIcon } from './UserIcon'
export const Navbar = () => {
// omit hooks
if (isLoggedIn) {
const onLogoutClicked = () => {
dispatch(logout())
}
const fetchNewNotifications = () => {
dispatch(fetchNotificationsWebsocket())
}
¡Casi lo tenemos! Estamos obteniendo notificaciones iniciales mediante RTK Query, rastreando el estado de lectura en el cliente, y tenemos la infraestructura configurada para forzar nuevas notificaciones mediante websocket. Pero, si hacemos clic en "Refresh Notifications" ahora, dará un error: ¡aún no hemos implementado el manejo del websocket!
Así que implementemos la lógica real de actualizaciones en streaming.
Implementación de actualizaciones en streaming
Para esta aplicación, conceptualmente queremos comprobar notificaciones tan pronto como el usuario inicie sesión, y comenzar inmediatamente a escuchar todas las actualizaciones futuras de notificaciones. Si el usuario cierra sesión, debemos dejar de escuchar.
Sabemos que <Navbar> solo se renderiza después de que el usuario inicia sesión, y permanece renderizado todo el tiempo. Así que sería un buen lugar para mantener viva la suscripción a la caché. Podemos hacerlo renderizando el hook useGetNotificationsQuery() en ese componente.
// omit other imports
import {
fetchNotificationsWebsocket,
selectUnreadNotificationsCount,
useGetNotificationsQuery
} from '@/features/notifications/notificationsSlice'
export const Navbar = () => {
const dispatch = useAppDispatch()
const user = useAppSelector(selectCurrentUser)
// Trigger initial fetch of notifications and keep the websocket open to receive updates
useGetNotificationsQuery()
// omit rest of the component
}
El último paso es añadir realmente el manejador del ciclo de vida onCacheEntryAdded a nuestro endpoint getNotifications, y añadir la lógica para trabajar con el websocket.
En este caso, vamos a crear un nuevo websocket, suscribirnos a mensajes entrantes desde el socket, leer las notificaciones de esos mensajes y actualizar la entrada de caché de RTKQ con los datos adicionales. Esto es conceptualmente similar a lo que hicimos con las actualizaciones optimistas en onQueryStarted.
Hay otro problema con el que nos encontraremos aquí. Si estamos recibiendo notificaciones entrantes mediante websocket, no se despacha una acción explícita de "solicitud exitosa", pero aún necesitamos crear nuevas entradas de metadatos de notificación para todas las notificaciones entrantes.
Abordaremos esto creando un nuevo tipo de acción específico de Redux que se usará solo para señalar que "hemos recibido más notificaciones", y despacharemos esa acción desde el manejador del websocket. Luego podemos actualizar notificationsSlice para escuchar tanto la acción del endpoint como esta otra acción usando la utilidad de coincidencia isAnyOf, y aplicar la misma lógica de metadatos en ambos casos.
import {
createEntityAdapter,
createSlice,
createSelector,
createAction,
isAnyOf
} from '@reduxjs/toolkit'
// omit imports and other code
const notificationsReceived = createAction<ServerNotification[]>('notifications/notificationsReceived')
export const apiSliceWithNotifications = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query<ServerNotification[], void>({
query: () => '/notifications',
async onCacheEntryAdded(arg, lifecycleApi) {
// create a websocket connection when the cache subscription starts
const ws = new WebSocket('ws://localhost')
try {
// wait for the initial query to resolve before proceeding
await lifecycleApi.cacheDataLoaded
// when data is received from the socket connection to the server,
// update our query result with the received message
const listener = (event: MessageEvent<string>) => {
const message: {
type: 'notifications'
payload: ServerNotification[]
} = JSON.parse(event.data)
switch (message.type) {
case 'notifications': {
lifecycleApi.updateCachedData(draft => {
// Insert all received notifications from the websocket
// into the existing RTKQ cache array
draft.push(...message.payload)
draft.sort((a, b) => b.date.localeCompare(a.date))
})
// Dispatch an additional action so we can track "read" state
lifecycleApi.dispatch(notificationsReceived(message.payload))
break
}
default:
break
}
}
ws.addEventListener('message', listener)
} catch {
// no-op in case `cacheEntryRemoved` resolves before `cacheDataLoaded`,
// in which case `cacheDataLoaded` will throw
}
// cacheEntryRemoved will resolve when the cache subscription is no longer active
await lifecycleApi.cacheEntryRemoved
// perform cleanup steps once the `cacheEntryRemoved` promise resolves
ws.close()
}
})
})
})
export const { useGetNotificationsQuery } = apiSliceWithNotifications
const matchNotificationsReceived = isAnyOf(
notificationsReceived,
apiSliceWithNotifications.endpoints.getNotifications.matchFulfilled,
)
// omit other code
const notificationsSlice = createSlice({
name: 'notifications',
initialState,
reducers: { /* omit reducers */ },
extraReducers(builder) {
builder.addMatcher(matchNotificationsReceived, (state, action) => {
// omit logic
}
},
})
Cuando se añade la entrada de caché, creamos una nueva instancia de WebSocket que se conectará al backend del servidor simulado.
Esperamos a que se resuelva la promesa lifecycleApi.cacheDataLoaded, momento en el que sabemos que la solicitud ha completado y tenemos datos reales disponibles.
Necesitamos suscribirnos a los mensajes entrantes del websocket. Nuestro callback recibirá un MessageEvent del websocket, y sabemos que event.data será una cadena que contiene los datos de notificaciones serializados en JSON desde el backend.
Cuando recibamos ese mensaje, parseamos el contenido y confirmamos que el objeto analizado coincide con el tipo de mensaje que buscamos. Si es así, llamamos a lifecycleApi.updateCachedData(), añadimos todas las nuevas notificaciones a la entrada de caché existente y las reordenamos para asegurarnos de que estén en el orden correcto.
Finalmente, también podemos esperar a que se resuelva la promesa lifecycleApi.cacheEntryRemoved para saber cuándo debemos cerrar el websocket y realizar la limpieza.
Ten en cuenta que no es obligatorio crear el websocket aquí en el método del ciclo de vida. Dependiendo de la estructura de la aplicación, podrías haberlo creado antes durante la configuración inicial, y podría estar ubicado en otro archivo de módulo o en su propio middleware de Redux. Lo realmente importante aquí es que estamos usando onCacheEntryAdded para saber cuándo empezar a escuchar datos entrantes, insertar los resultados en la entrada de caché y limpiar cuando esta desaparezca.
¡Y eso es todo! Ahora, al hacer clic en "Actualizar notificaciones", deberíamos ver aumentar el contador de notificaciones no leídas, y al ir a la pestaña "Notificaciones" se resaltarán apropiadamente las leídas y no leídas.
Limpieza final
Como paso final, podemos realizar una limpieza adicional. La llamada real a createSlice en postsSlice.ts ya no se utiliza, así que podemos eliminar el slice y sus selectores + tipos asociados, luego quitar postsReducer del store de Redux. Dejaremos la función addPostsListeners y los tipos ahí, ya que es un lugar razonable para ese código.
Lo que has aprendido
Con esto, ¡hemos terminado de convertir nuestra aplicación para usar RTK Query! Toda la obtención de datos se ha cambiado a RTKQ, y hemos mejorado la experiencia de usuario añadiendo actualizaciones optimistas y streaming de actualizaciones.
Como hemos visto, RTK Query incluye potentes opciones para controlar cómo gestionamos los datos en caché. Aunque quizá no necesites todas estas opciones inmediatamente, proporcionan flexibilidad y capacidades clave para implementar comportamientos específicos de la aplicación.
Echemos un último vistazo a toda la aplicación en funcionamiento:
- Se pueden usar etiquetas de caché específicas para una invalidación más granular
- Las etiquetas pueden ser
'Post'o{type: 'Post', id} - Los endpoints pueden proporcionar o invalidar etiquetas basadas en claves de caché de resultados y argumentos
- Las etiquetas pueden ser
- Las APIs de RTK Query son agnósticas a la UI y pueden usarse fuera de React
- Los objetos de endpoint incluyen funciones para iniciar peticiones, generar selectores de resultados y hacer match con acciones de solicitud
- Las respuestas pueden transformarse de diferentes formas según sea necesario
- Los endpoints pueden definir un callback
transformResponsepara modificar datos antes de cachearlos - Los hooks pueden recibir una opción
selectFromResultpara extraer/transformar datos - Los componentes pueden leer un valor completo y transformarlo con
useMemo
- Los endpoints pueden definir un callback
- RTK Query tiene opciones avanzadas para manipular datos en caché y mejorar la UX
- El ciclo de vida
onQueryStartedpermite actualizaciones optimistas modificando la caché antes de que la petición responda onCacheEntryAddedpermite streaming de actualizaciones modificando la caché en tiempo real basado en conexiones push del servidor- Los endpoints de RTKQ tienen un matcher
matchFulfilledque puede usarse para escuchar acciones de endpoints y ejecutar lógica adicional, como actualizar el estado de un slice
- El ciclo de vida
¿Qué sigue?
¡Enhorabuena, has completado el tutorial de Redux Essentials! Ahora deberías tener una comprensión sólida de qué son Redux Toolkit y React-Redux, cómo escribir y organizar lógica de Redux, el flujo de datos en Redux y su uso con React, y cómo usar APIs como configureStore y createSlice. También deberías saber cómo RTK Query puede simplificar el proceso de obtener y usar datos cacheados.
Para más detalles sobre cómo usar RTK Query, consulta la guía de uso de RTK Query y la referencia de la API.
Los conceptos que hemos cubierto en este tutorial deberían ser suficientes para que empieces a construir tus propias aplicaciones usando React y Redux. Ahora es un buen momento para trabajar en un proyecto propio y consolidar estos conceptos viendo cómo funcionan en la práctica. Si no estás seguro de qué tipo de proyecto crear, echa un vistazo a esta lista de ideas para aplicaciones para inspirarte.
El tutorial de Redux Essentials se centra en "cómo usar Redux correctamente", más que en "cómo funciona" o "por qué funciona así". En particular, Redux Toolkit es un conjunto de abstracciones y utilidades de alto nivel, y es útil entender qué están haciendo realmente las abstracciones de RTK por ti. Leer el tutorial de "Fundamentos de Redux" te ayudará a entender cómo escribir código Redux "manualmente" y por qué recomendamos Redux Toolkit como la forma predeterminada de escribir lógica Redux.
La sección Usando Redux contiene información sobre varios conceptos importantes, como cómo estructurar tus reductores, y nuestra Guía de estilo tiene información crucial sobre los patrones y mejores prácticas recomendados.
Si quieres saber más sobre por qué existe Redux, qué problemas intenta resolver y cómo está diseñado para usarse, consulta las publicaciones del mantenedor de Redux Mark Erikson sobre El Tao de Redux, Parte 1: Implementación e intención y El Tao de Redux, Parte 2: Práctica y filosofía.
Si necesitas ayuda con dudas sobre Redux, únete al canal #redux en el servidor de Discord de Reactiflux.
¡Gracias por leer este tutorial y esperamos que disfrutes construyendo aplicaciones con Redux!